
Warum Hadoop?
Hadoop bietet ein stabiles Grundgerüst bestehend aus HDFS, Yarn und MapReduce – auf dieses lassen sich Tools aufsetzen, um die im HFDS gespeicherten Daten zu analysieren oder weiter zu verarbeiten. In unserem Fall sollen SQL ähnliche Lösungen verwendet werden.
Ziel war es eine bekannte Umgebung vorzufinden und mit vorhandenen Kenntnissen (Hauptsächlich SQL und Bash, etwas Python/PySpark) eine Testinstallation aufzusetzen.
Die Daten selber werden auf unterschiedliche Weise übernommen bzw. aufbereitet, um mehrere Möglichkeiten auszuprobieren.
- Mittels eines bash scripts werden täglich csv’s abgeholt und an eine bestehende Datei im HDFS angehängt. Über HIVE wird eine Tabelle angelegt die auf dieses csv zeigt
- Mittels sqoop werden Daten von einem SQL Server direkt in eine HIVE-Warehouse Tabelle übernommen
- Übernahme von csv’s, Aufbereitung mittels Python/PySpark und Import in eine HIVE-Warehouse Tabelle
Verwendete Hardware
Für die Installation wurden 3 virtuelle Maschinen mit Linux auf einem vorhandenen Hyper-V Server angelegt.
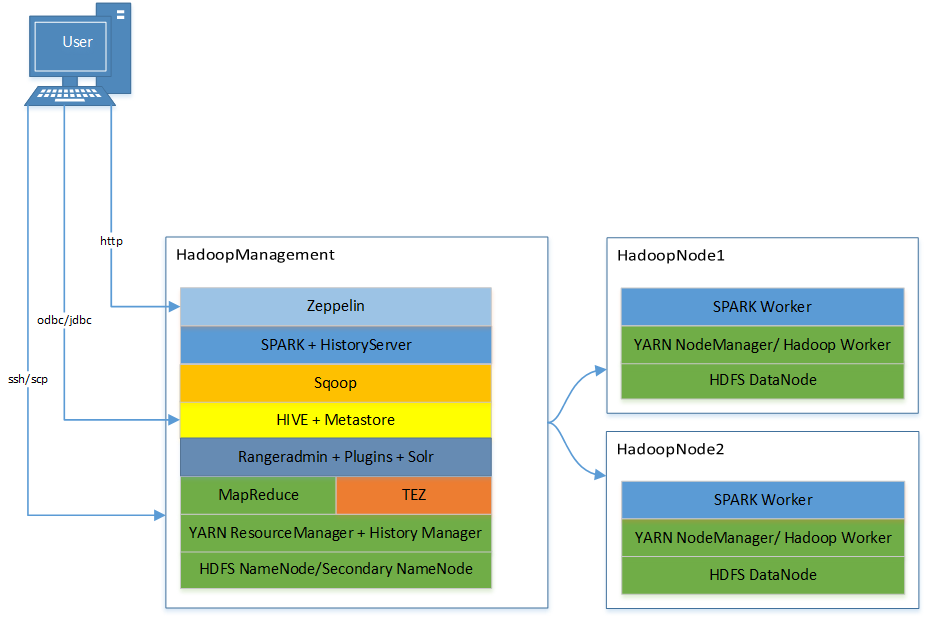
Es gibt eine Management VM (Cluster start/stop, hdfs/ssh/scp Zugriff für User) sowie 2 Node VM’s (DataNodes, Worker).
Hostname: HadoopManagement
Betriebssystem: Ubuntu 16.04 LTS Server
IP: 192.168.1.235
RAM: 8GB
CPU: 2 Cores
HDD: 120GB
Hostname: HadoopNode1
Betriebssystem: Ubuntu 16.04 LTS Server
IP: 192.168.1.236
RAM: 6GB
CPU: 2 Cores
HDD: 120GB
Hostname: HadoopNode2
Betriebssystem: Ubuntu 16.04 LTS Server
IP: 192.168.1.237
RAM: 6GB
CPU: 2 Cores
HDD: 120GB
Verwendete Software
Ubuntu Server 16.04 LTS
Es wurde eine Standardinstallation von Ubuntu verwendet (Englische Sprache mit deutschem Tastaturlayout).
Obwohl Ubuntu 18.04 aktuell war, wurde die Version 16.04 genommen – hier gab es keine Probleme beim kompilieren von Apache Ranger sowie beim Aktivieren der verwendeten Plugins.
Zur Zeitsynchronisation wird ntpdate aus den Ubuntuquellen verwendet.
JAVA 8 (openjdk-8)
Das in Ubuntu vorhandene Paket openjdk-8-jdk-headless wurde verwendet.
Ranger 1.2.0
Aktuelle stabile Version.
Große Abhängigkeiten für nachfolgende Pakete – die entsprechenden Versionen könnten aus der pom.xml rausgelesen werden.
Es werden die Zugriffe auf HDFS und Hive berechtigt und zusätzlich die Zugriffe in Solr geloggt.
Solr kann bei der Installation des Rangeradmin’s mit installiert werden.
Hadoop 2.7.7
Aktuelle stabile Version und mit Ranger 1.2.0 kompatibel.
HDFS wird für das Hive Warehouse sowie zur Speicherung der Daten verwendet bzw. YARN zur Ressourcenverwaltung/verteilung verwendet.
Daten werden per SSH/SCP über den HadoopManagement Server in’s HDFS übertragen.
Apache Hive 2.3.4
Aktuelle 2.3.x Version und mit Ranger 1.2.0 kompatibel.
Wird für SQL Abfragen der Daten im HDFS verwendet bzw. der Daten im Hive Warehouse.
Mit dem enthaltenen JDBC Treiber kann z.B. Squirrel SQL für den Hive Zugriff und Auswertungen verwendet werden.
Mit einem ODBC Treiber könnten die Daten z.B. in Power BI verwendet werden.
Apache Tez 0.9.2
Aktuelle stabile Version.
Wird statt MapReduce verwendet für bessere Performance.
Sqoop 1.4.7
Aktuelle stabile Version, musste mit einem Patch für Hadoop 2.7.7 kompatibel gemacht werden.
Wird verwendet um Daten von z.B. SQL Server in’s Hive Warehouse zu übertragen.
Spark 2.4.3
Aktuelle stabile Version, die mit Hive Metastore 2.3.4 kompatibel ist.
Wird für SQL Abfragen der Daten im HDFS verwendet bzw. der Daten im Hive Warehouse.
Zusätzlich können Daten für das Hive Warehouse aufbereitet werden.
Zeppelin 0.8.2
Aktuelle stabile Version.
GUI für Hive/Spark Abfragen und für Spark Scala/Python Scripts.
Installationsablauf

Cluster Übersicht mit Services
Erfahrungen
Weil eine Hortonworks Testinstallation nicht wie gewünscht funktionierte, wurde der Cluster händisch installiert und konfiguriert. Daraus ergab sich ein höherer Installationsaufwand, und es war nötig, sich mehr mit der Materie zu beschäftigt, wie die einzelnen Komponenten miteinander zusammenspielen.
Da das Hadoop Ökosystem umfangreich ist, sollte im Vorhinein abgeklärt werden, welche Tools zum Einsatz kommen sollen und wie man sie verwenden will.
Oft müssen Fehler recherchiert werden, Lösungen sind eventuell nicht immer möglich und es müssen andere Tools eruiert werden.
Viele Abhängigkeiten ergeben sich durch Ranger. Falls Security/Logging ein Thema ist, sollte dieser so früh wie möglich eingebunden werden und die Versionen der zu verwendenden Tools darauf abgestimmt werden.
Die Installation in virtuellen Maschinen macht das Erstellen von Backups einfacher.
Wenn der Cluster wie gewünscht läuft, treten relativ selten Fehler auf. Dadurch ist der Administationsaufwand auf einem niedrigen Level. Da es sich jedoch um einen Testcluster handelt, könnte produktiv mit viel Last und Usern das Verhalten ein anderes sein.

