MySQL trifft Big Data
Was ist Doris?
Bei Apache Doris handelt es sich um eine MPP (Massively Parallel Processing) Datenbank für Big Data mit Kompatibilität zum MySQL Protokoll.
Daten müssen allerdings klassisch in die Doris Datenbanktabellen geladen werden. Dafür sollten die Daten eine einheitliche Struktur haben.
Die Datenquellen können unterschiedlich sein. Für den Import können die Daten u.a. von Apache Hadoop gelesen werden.
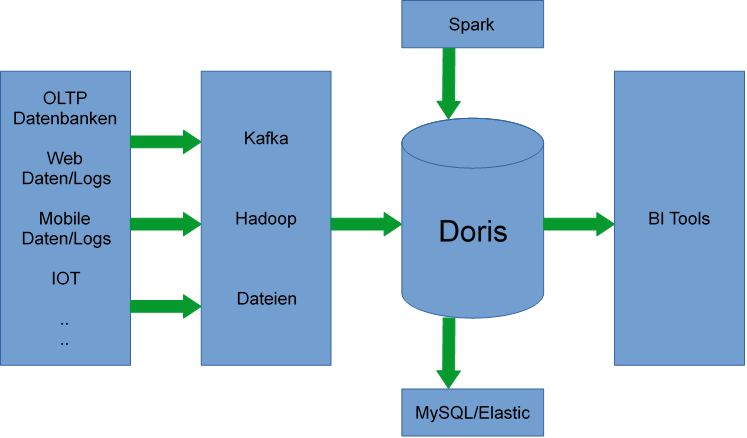
Für den Zugriff auf und das Abfragen von den importierten Daten können vorhandene ODBC/JDBC Treiber verwendet werden.
Ubuntu installieren und einrichten
Wir werden einen Testcluster mit der Version 0.15 (vom 29.11.2021, zum Installationszeitpunkt aktuell) installieren und Daten über HDFS Laden.
Dazu starten wir mit der Ubuntu Installation von 3 Hosts, danach kommt Hadoop, Apache Doris und das Laden von Movielens Daten.
Verwendente Hosts
HadoopManagement → 192.168.42.245
Ubuntu 20.04 LTS, 2 Cores, 8192MB RAM
HadoopNode1 → 192.168.42.246
Ubuntu 20.04 LTS, 2 Cores, 8192MB RAM
HadoopNode2 → 192.168.42.247
Ubuntu 20.04 LTS, 2 Cores, 8192MB RAM
Netzwerk einrichten und anwenden
sudo vi /etc/netplan/01-netcfg.yaml network: version: 2 renderer: networkd ethernets: enp0s3: dhcp4: no addresses: [192.168.42.245/24] gateway4: 192.168.42.1 nameservers: addresses: [192.168.42.1,8.8.8.8]
sudo netplan apply
Hosts in /etc/hosts eintragen
sudo vi /etc/hosts 127.0.0.1 localhost #127.0.1.1 h3cl01 192.168.42.245 h3cl01 192.168.42.246 h3cl02 192.168.42.247 h3cl03 # The following lines are desirable for IPv6 capable hosts ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters hduser anlegen
sudo addgroup hadoop sudo adduser --ingroup hadoop hduser sudo usermod -aG sudo hduser
Java installieren: sudo apt install openjdk-11-jdk-headless
Hadoop Verzeichnisse anlegen sudo mkdir -p /data/hadoop/namenode sudo mkdir -p /data/hadoop/datanode sudo mkdir -p /data/hadoop/logs sudo chown -R hduser:hadoop /data/hadoop sudo chmod -R 775 /data/hadoop sudo chown -R hduser:hadoop /opt sudo chmod -R 775 /opt/ su - hduser
SSH-Keys verteilen ssh-keygen -t rsa -b 4096 -P "" ssh-copy-id hduser@h3cl01 ssh-copy-id hduser@h3cl02 ssh-copy-id hduser@h3cl03
Testen – es sollte eine Passworteingabe erscheinen
ssh h3cl01 ssh h3cl02 ssh h3cl03
Hadoop installieren
Hadoop herunterladen und nach /opt entpacken
wget -c https://mirror.klaus-uwe.me/apache/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz tar xvpf hadoop-3.3.1.tar.gz -C /opt/ cd /opt/ ln -s hadoop-3.3.1 hadoop
Hadoop Variablen setzen
cd vi .profile export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 PATH=$PATH:/opt/hadoop/bin PATH=$PATH:/opt/hadoop/sbin export HADOOP_HOME=/opt/hadoop export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export HADOOP_LOG_DIR=/data/hadoop/logs export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native" export YARN_HOME=$HADOOP_HOME export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native export CLASSPATH=$CLASSPATH:/opt/hadoop/lib/* export CLASSPATH=$CLASSPATH:/opt/hadoop/lib/native/* vi /opt/hadoop/etc/hadoop/hadoop-env.sh #export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export HADOOP_LOG_DIR=/data/hadoop/logs vi /opt/hadoop/etc/hadoop/mapred-env.sh export HADOOP_LOG_DIR=/data/hadoop/logs vi /opt/hadoop/etc/hadoop/yarn-env.sh export HADOOP_LOG_DIR=/data/hadoop/logs
Hadoop konfigurieren
vi /opt/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://h3cl01:9000</value>
</property>
</configuration>
vi /opt/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hadoop/nameNode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop/dataNode</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions.superusergroup</name>
<value>hadoop</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>h3cl02:50090</value>
</property>
</configuration>
vi /opt/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>768</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>1536</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx614m</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx1228m</value>
</property>
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>307</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop</value>
</property>
</configuration>
vi /opt/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.acl.enable</name>
<value>0</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>h3cl01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4608</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4608</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1536</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>768</value>
</property>
<property>
<name>yarn.app.mapreduce.am.command-opts</name>
<value>-Xmx614m</value>
</property>
<property>
<name>yarn.timeline-service.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.timeline-service.hostname</name>
<value>h3cl01</value>
</property>
<property>
<name>yarn.timeline-service.http-cross-origin.enabled</name>
<value>true</value>
</property>
<property>
<name> yarn.resourcemanager.system-metrics-publisher.enabled</name>
<value>true</value>
</property>
</configuration>
vi /opt/hadoop/etc/hadoop/workers
h3cl02
h3cl03
.profile und Hadoop auf die anderen Hosts verteilen
scp ~/.profile h3cl02:~/ scp ~/.profile h3cl03:~/ rsync -aAvh /opt/*hadoop* h3cl02:/opt/ rsync -aAvh /opt/*hadoop* h3cl03:/opt/
NameNode formatieren
hdfs namenode -format
Hadoop starten
start-dfs.sh http://192.168.42.245:9870 start-yarn.sh yarn node -list http://192.168.42.245:8088 mapred --daemon start historyserver http://192.168.42.245:19888 yarn --daemon start timelineserver http://192.168.42.245:8188
Doris installieren
Doris & Broker kompilieren
Server: h3cl01
Docker installieren und Build Environment herunterladen
sudo apt-get install docker.io sudo apt install mariadb-client-core-10.3 net-tools
cd mkdir builds cd builds sudo docker pull apache/incubator-doris:build-env-1.4.1 wget -c https://dlcdn.apache.org/incubator/doris/0.15.0-incubating/apache-doris-0.15.0-incubating-src.tar.gz tar xpf apache-doris-0.15.0-incubating-src.tar.gz sudo docker run -it -v /root/.m2:/root/.m2 -v /home/hduser/builds/apache-doris-0.15.0-incubating-src:/root/incubator-doris-DORIS-0.15.0-release/ apache/incubator-doris:build-env-1.4.1
Doris kompilieren
cd incubator-doris-DORIS-0.15.0-release WITH_MYSQL=1 ./build.sh
→ fe und be Ordner liegen unter output
cd fs_brokers/apache_hdfs_broker/ ./build.sh
→ apache_hdfs_broker Ordner liegt unter output
exit
docker.io deaktivieren
sudo systemctl disable docker.io
→ kontrollieren mit ifconfig ob das Interface docker0 weg ist, sonst läuft doris auf dessen IP
ulimits setzen
Server: h3cl01/h3cl02/h3cl03
sudo vim /etc/security/limits.conf hduser soft nproc 65535 hduser hard nproc 65535 hduser soft nofile 65535 hduser hard nofile 65535 sudo reboot
FE (Frontend) installieren und konfigurieren
Server: h3cl01
cp -r builds/apache-doris-0.15.0-incubating-src/output/fe /opt/
cd /opt/
mv fe apache-doris-0.15.0_fe
ln -s apache-doris-0.15.0_fe doris
cd doris
mkdir doris-meta
vi /conf/fe.conf
# the output dir of stderr and stdout
LOG_DIR = ${DORIS_HOME}/log
DATE = `date +%Y%m%d-%H%M%S`
JAVA_OPTS="-Xmx4096m -XX:+UseMembar -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=7 -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSClassUnloadingEnabled -XX:-CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -Xloggc:$DORIS_HOME/log/fe.gc.log.$DATE"
# For jdk 9+, this JAVA_OPTS will be used as default JVM options
JAVA_OPTS_FOR_JDK_9="-Xmx4096m -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=7 -XX:+CMSClassUnloadingEnabled -XX:-CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -Xlog:gc*:$DORIS_HOME/log/fe.gc.log.$DATE:time"
##
## the lowercase properties are read by main program.
##
# INFO, WARN, ERROR, FATAL
sys_log_level = INFO
# store metadata, must be created before start FE.
# Default value is ${DORIS_HOME}/doris-meta
meta_dir = ${DORIS_HOME}/doris-meta
http_port = 9080
query_port = 9030
edit_log_port = 9010
mysql_service_nio_enabled = true
# Choose one if there are more than one ip except loopback address.
# Note that there should at most one ip match this list.
# If no ip match this rule, will choose one randomly.
# use CIDR format, e.g. 10.10.10.0/24
# Default value is empty.
# priority_networks = 10.10.10.0/24;192.168.0.0/16
priority_networks = 192.168.42.0/24
# Advanced configurations
# log_roll_size_mb = 1024
sys_log_dir = ${DORIS_HOME}/log
# sys_log_roll_num = 10
# sys_log_verbose_modules =
# audit_log_dir = ${DORIS_HOME}/log
# audit_log_modules = slow_query, query
# audit_log_roll_num = 10
# meta_delay_toleration_second = 10
# qe_max_connection = 1024
# max_conn_per_user = 100
# qe_query_timeout_second = 300
# qe_slow_log_ms = 5000
cd
vi .profile
export DORIS_HOME=/opt/doris
source .profile
.profile auf die anderen Hosts verteilen
scp ~/.profile h3cl02:~/ scp ~/.profile h3cl03:~/
Frontend starten
Server: h3cl01
/opt/doris/bin/start_fe.sh --daemon
Backends hinzufügen
mysql -h h3cl01 -P 9030 -uroot ALTER SYSTEM ADD BACKEND "h3cl02:9050"; ALTER SYSTEM ADD BACKEND "h3cl03:9050";
Broker hinzufügen
mysql -h h3cl01 -P 9030 -uroot ALTER SYSTEM ADD BROKER broker_name "h3cl01:8000","h3cl02:8000","h3cl03:8000";
BE (Backend) installieren und konfiguriern
Server: h3cl01
Broker auf h3cl02/h3cl03 kopieren mit rsync
cd /home/hduser/builds/apache-doris-0.15.0-incubating-src/output/ rsync -aAvh be h3cl02:/opt/ rsync -aAvh be h3cl03:/opt/
Server: h3cl02/h3cl03
sudo apt install mariadb-client-core-10.3 net-tools
cd /opt/
mv be apache-doris-0.15.0_be
ln -s apache-doris-0.15.0_be doris
cd doris
mkdir storage
vi conf/be.conf
PPROF_TMPDIR="$DORIS_HOME/log/"
# INFO, WARNING, ERROR, FATAL
sys_log_level = INFO
# ports for admin, web, heartbeat service
be_port = 9060
webserver_port = 9040
heartbeat_service_port = 9050
brpc_port = 8060
# Choose one if there are more than one ip except loopback address.
# Note that there should at most one ip match this list.
# If no ip match this rule, will choose one randomly.
# use CIDR format, e.g. 10.10.10.0/24
# Default value is empty.
priority_networks = 192.168.42.0/24
# data root path, separate by ';'
# you can specify the storage medium of each root path, HDD or SSD
# you can add capacity limit at the end of each root path, seperate by ','
# eg:
# storage_root_path = /home/disk1/doris.HDD,50;/home/disk2/doris.SSD,1;/home/disk2/doris
# /home/disk1/doris.HDD, capacity limit is 50GB, HDD;
# /home/disk2/doris.SSD, capacity limit is 1GB, SSD;
# /home/disk2/doris, capacity limit is disk capacity, HDD(default)
#
# you also can specify the properties by setting '<property>:<value>', seperate by ','
# property 'medium' has a higher priority than the extension of path
#
# Default value is ${DORIS_HOME}/storage, you should create it by hand.
storage_root_path = ${DORIS_HOME}/storage
# Advanced configurations
sys_log_dir = ${DORIS_HOME}/log
# sys_log_roll_mode = SIZE-MB-1024
# sys_log_roll_num = 10
# sys_log_verbose_modules = *
# log_buffer_level = -1
# palo_cgroups
Backend starten
Server: h3cl02/h3cl03
/opt/doris/bin/start_be.sh --daemon
Kontrolle mit
netstat, ps -ef, logfiles
Broker installieren
Server: h3cl01
cd /home/hduser/builds/apache-doris-0.15.0-incubating-src/fs_brokers/apache_hdfs_broker/output cp -rp apache_hdfs_broker /opt/ cd /opt/ ln -s apache_hdfs_broker doris_broker cd doris_broker/conf ln -s /opt/hadoop/etc/hadoop/hdfs-site.xml . ln -s /opt/hadoop/etc/hadoop/core-site.xml . vi apache_hdfs_broker.conf # the thrift rpc port broker_ipc_port=8000 # client session will be deleted if not receive ping after this time client_expire_seconds=300
Broker auf h3cl02/h3cl03 kopieren mit rsync
cd /opt/ rsync -aAvh *broker* h3cl02:/opt/ rsync -aAvh *broker* h3cl03:/opt/
Broker starten
Server: h3cl01/h3cl02/h3cl03
/opt/doris_broker/bin/start_broker.sh --daemon
Status checken
mysql -h h3cl01 -P 9030 -uroot -e "SHOW PROC '/frontends';"

mysql -h h3cl01 -P 9030 -uroot -e "SHOW PROC '/backends';"mysql -h h3cl01 -P 9030 -uroot -e "SHOW PROC '/brokers';"

Movielens DB
Anmerkung
Die Movielens Daten enthalten Encapsulations, die Daten konnten nicht importieren werden, da Doris diese beim Broker Load nicht unterstützt.
Die betroffenen Zeilen wurden einfachheitshalber entfernt mit dem Befehl:
cat movies.csv |grep -v "\"" > movies_list.csv
Die Datei movies_list.csv wurde dann auf movies.csv umbenannt.
Aktuelle Version herunterladen und ins hdfs kopieren
cd
sudo apt-get install unzip
wget -c http://files.grouplens.org/datasets/movielens/ml-latest.zip
unzip ml-latest.zip
mv ml-latest movielens
cd movielens
rm README.txt
mkdir $(ls *.csv |cut -d "." -f1)
for i in $(ls *.csv); do mv ${i} $(echo ${i} |cut -d "." -f1); done
movielens Dateien ins HDFS kopieren
cd .. hdfs dfs -mkdir -p /tmp_import hdfs dfs -put movielens /tmp_import/ hdfs dfs -chmod -R 777 /tmp_import rm -rf movielens
Datenbank und Tabellen anlegen
CREATE database movielens;
CREATE TABLE movielens.movies (
itemID INT,
title VARCHAR(255),
genre VARCHAR(255)
)
--UNIQUE KEY (itemID) UNIT
DISTRIBUTED BY HASH(itemID) BUCKETS 10
PROPERTIES("replication_num" = "2");
CREATE TABLE movielens.ratings (
userID INT ,
itemID INT ,
rating DOUBLE,
timestamp INT
)
--DUPLICATE KEY (userID, itemID)
DISTRIBUTED BY HASH(userID,itemID) BUCKETS 10
PROPERTIES("replication_num" = "2");
Tabellen befüllen (Broker Load von HDFS
LOAD LABEL movielens.movies_20211210_1
(
DATA INFILE("hdfs://h3cl01:9000/tmp_import/movielens/movies/movies_list.csv")
INTO TABLE movies
COLUMNS TERMINATED BY ';'
)WITH BROKER 'broker_name'
(
"username"="hduser",
"password"="hduser"
)
PROPERTIES
(
"timeout" = "3600"
);
LOAD LABEL movielens.ratings_20211210_1
(
DATA INFILE("hdfs://h3cl01:9000/tmp_import/movielens/ratings/ratings.csv")
INTO TABLE ratings
COLUMNS TERMINATED BY ';'
)
WITH BROKER 'broker_name'
(
"username"="hduser",
"password"="hduser"
)
PROPERTIES
(
"timeout" = "3600"
);
Broker LOAD überprüfen
mysql -h h3cl01 -P 9030 -uroot use movielens; SHOW LOAD WHERE LABEL = "movies_20211210_1"; SHOW LOAD WHERE LABEL = "ratings_20211210_1";
Testauswertung
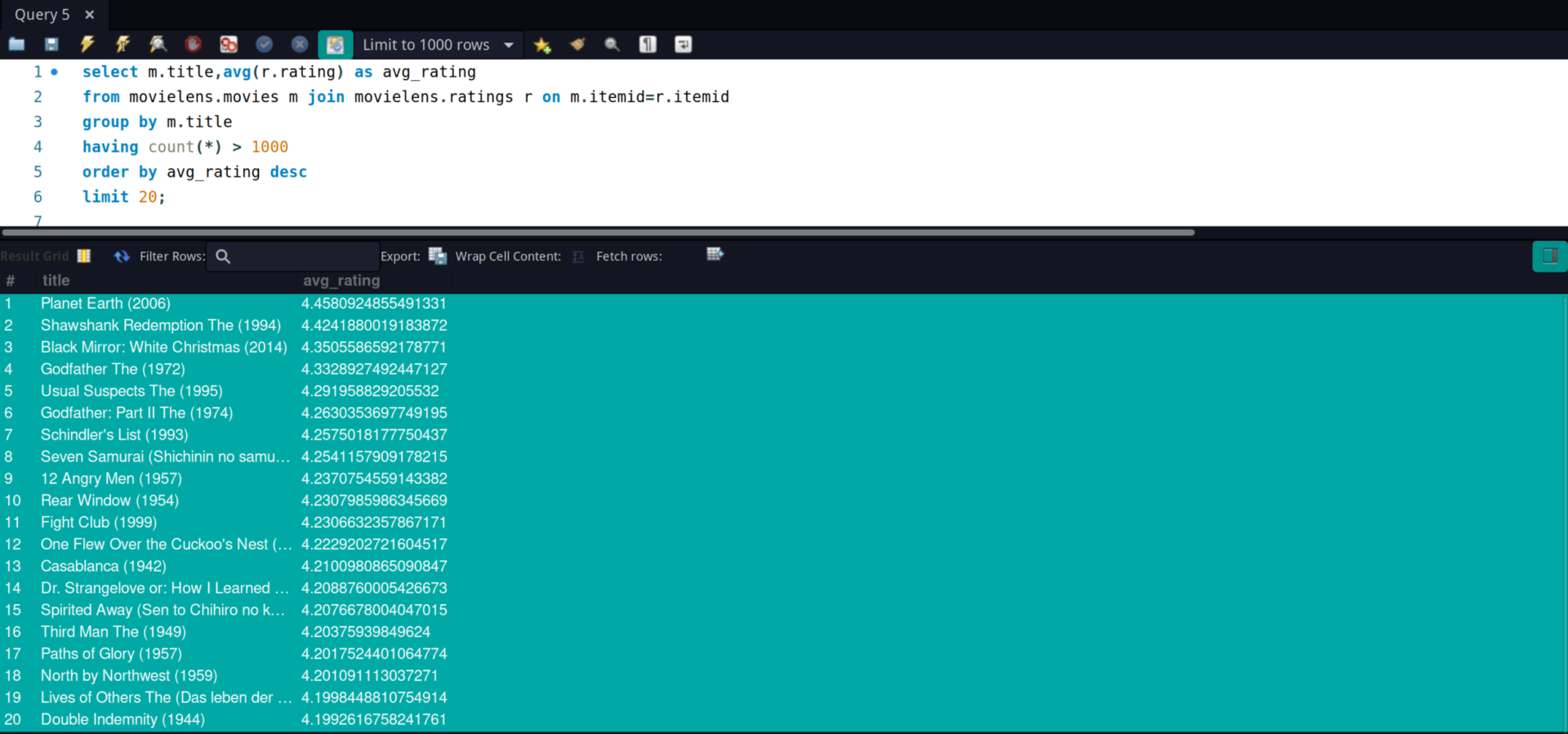
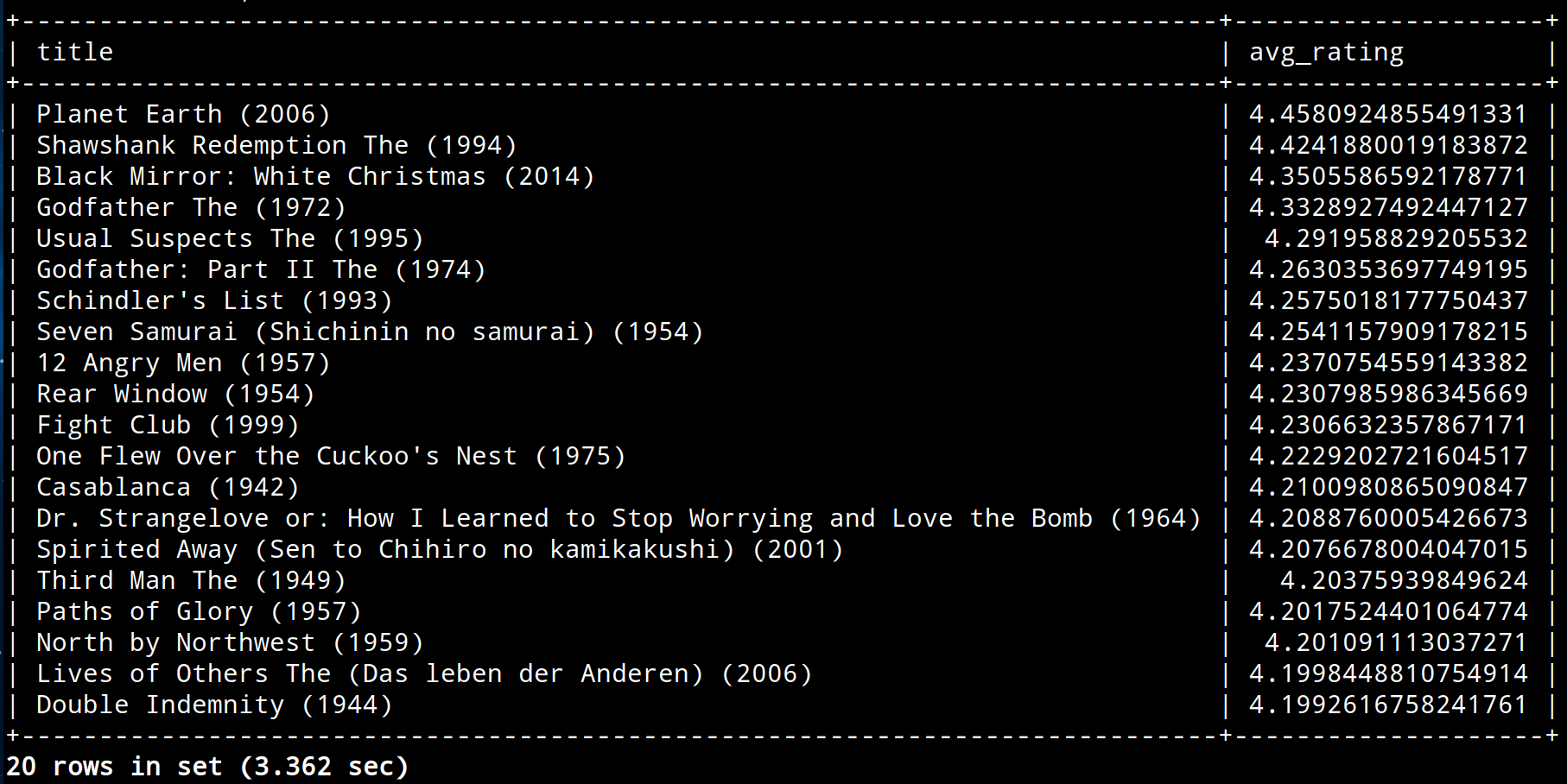
select m.title,avg(r.rating) as avg_rating from movielens.movies m join movielens.ratings r on m.itemid=r.itemid group by m.title having count(*) > 1000 order by avg_rating desc limit 20;
Fazit
Die Installation und Konfiguration für ein Testsystem funktioniert gut nach Anleitung. Auf Security und Usermanagement wurde in unserem Fall allerdings verzichtet.
Die Einarbeitungszeit für z.B. Auswertungen sollte gering ausfallen, da es sich um eine Standard SQL Syntax handelt.
Obwohl wir vorhandene ODBC/JDBC Treiber verwenden können, sollte trotzdem eine 1:1 Übernahme von vorhandene Scripts und Abläufen nicht erwartet werden, da eventuell verwendete Funktionen nicht vorhanden sind oder anders funktionieren.
MySQL Workbench weist uns z.B. darauf hin, dass es sich beim Herstellen einer Verbindung nicht um eine kompatible Version handelt:
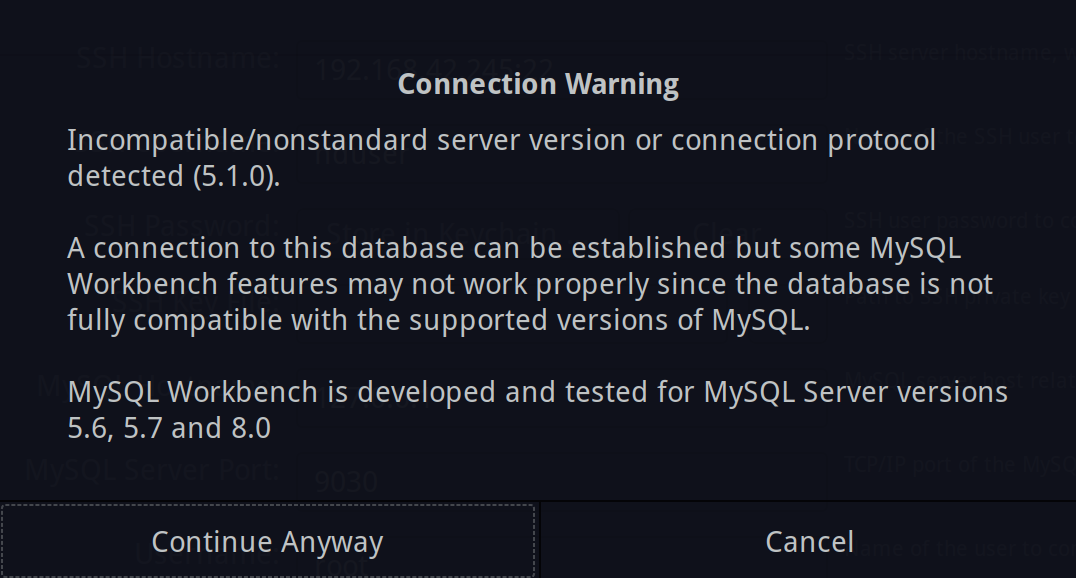
Die Verbindung kann allerdings trotzdem aufgebaut und unsere Testauswertung ausgeführt werden: