Einleitung
DuckDB ist ein serverloses In-Memory-Datenbankmanagementsystem (DBMS) für Data-Science-Anwendungen und kann mit unterschiedlichsten API’s und Programmiersprachen angesprochen werden.
In unserem Fall werden wir ein paar Beispiele zum Funktionsumfang mit der movielens Datenbank ausprobieren, mit dem Linux Client für die DuckDB arbeiten und SQL verwenden.
Aktuelle Version auf duckdb.org suchen und runterladen
Den Linux-Client können wir von github (duckdb.org) runterladen und einfach in unserem Home-Ordner entpacken:
- cd
- wget https://github.com/duckdb/duckdb/releases/download/v0.10.2/duckdb_cli-linux-amd64.zip
- unzip duckdb_cli-linux-amd64.zip

Sollten wir andere Clients benötigen, können wir alle möglichen verfügbaren Varianten von duckdb.org runterladen oder uns anzeigen lassen, wie wir die Clients installieren können.
Movielens runterladen und entpacken
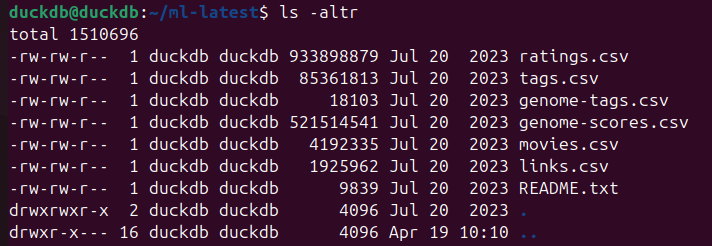
Wir laden die aktuelle movielens Datenbank und entpacken sie in unserem Home-Ordner:
- wget -c https://files.grouplens.org/datasets/movielens/ml-latest.zip
- unzip ml-latest.zip
- cd ml-latest
- ls -altr
DuckDB Starten
Jetzt können wir unseren DuckDB-Client starten und testweise ein Select auf die movies.csv Datei ausführen:
- ../duckdb
10.2 1601d94f94
Enter „.help“ for usage hints.
Connected to a transient in-memory database.
Use „.open FILENAME“ to reopen on a persistent database.
D select * from movies.csv limit 10;
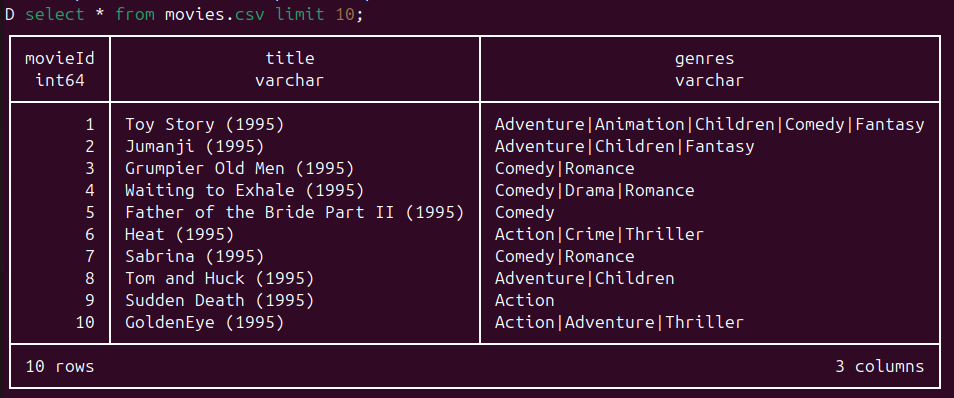
⇒ Da wir beim Starten des Clients keine .db Datei angegeben haben, bleibt alles im Arbeitsspeicher und es wird nichts auf unsere Festplatte geschrieben.
⇒ Sollten wir Auswertungen in Tabellen speichern oder Daten importieren wollen, müssen wir den Client mit dem Zusatz des DB-Namens starten:
- ../duckdb movielens.db
10.2 1601d94f94
Enter „.help“ for usage hints.
D
Testauswertung
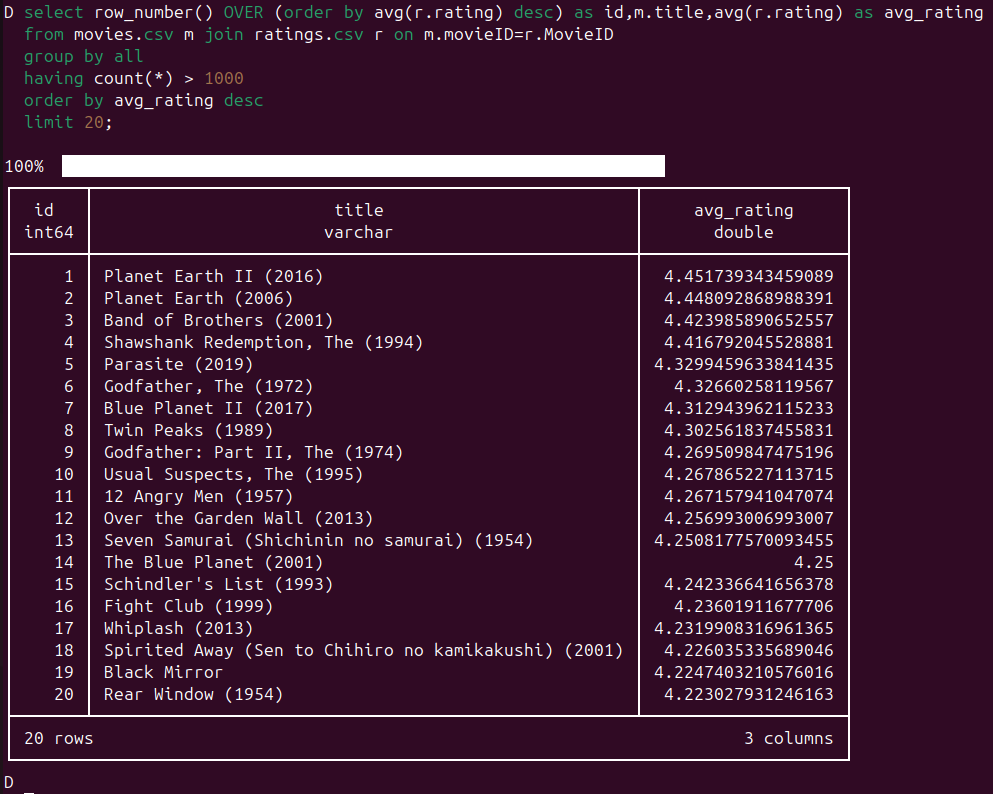
Zum Testen werden wir uns die Top 20 Filme ausgeben lassen, wobei es über 1000 Bewertungen zu einem Film geben soll.
Zusätzlich lassen wir uns noch eine ID für die Position vergeben:
select row_number() OVER (order by avg(r.rating) desc) as id,m.title,avg(r.rating) as avg_rating
from movies.csv m join ratings.csv r on m.movieID=r.MovieID
group by all
having count(*) > 1000
order by avg_rating desc
limit 20;
Sollten wir die Auswertung in einer Tabelle speichern wollen, müssen wir beim Start des Clients eine .db Datei angeben:
- ../duckdb movielens.db
Mit einem create table as können wir die Auswertung dann abspeichern:
create table top20 as (
select row_number() OVER (order by avg(r.rating) desc) as id,m.title,avg(r.rating) as avg_rating
from movies.csv m join ratings.csv r on m.movieID=r.MovieID
group by all
having count(*) > 1000
order by avg_rating desc
limit 20
);
Nach dem Beenden des Clients sehen wir unsere movielens.db Datei

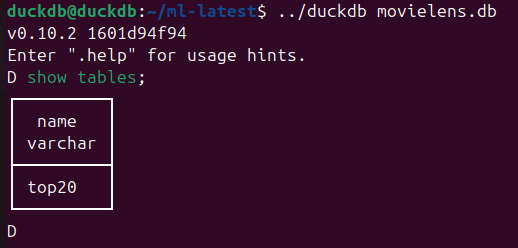
Wenn wir den Client nochmals starten und ein „show tables;“ ausführen, sehen wir unsere top20 Tabelle:
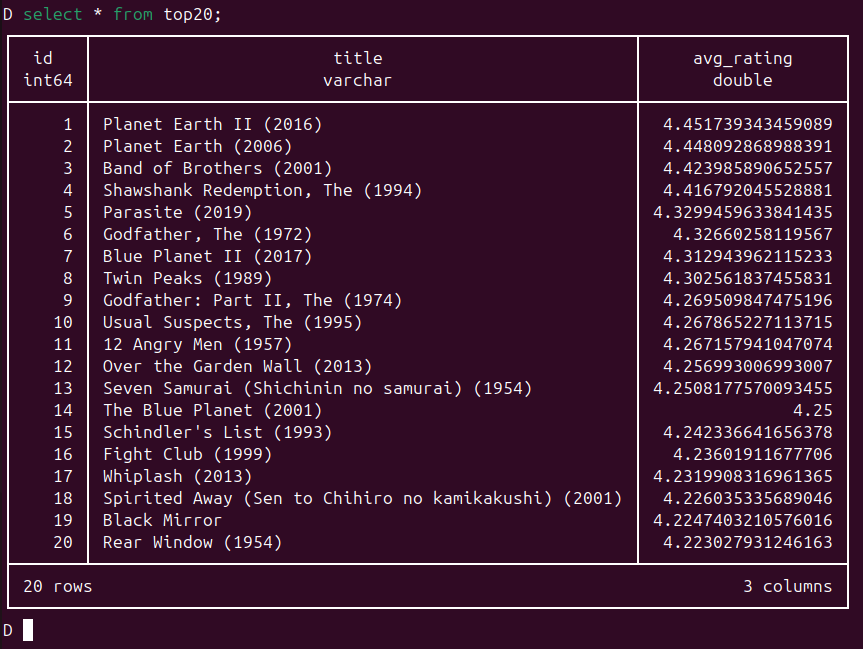
Ein „select * from top20;“ zeigt uns dann den Inhalt der Testauswertung:
Export der Auswertung in .csv Dateien
Unsere Testauswertung können wir jetzt direkt in eine .csv Datei exportieren,
das geschieht mit dem COPY-Befehl:
Export mit „;“ als Trennzeichen
COPY (
select row_number() OVER (order by avg(r.rating) desc) as id,m.title,avg(r.rating) as avg_rating
from movies.csv m join ratings.csv r on m.movieID=r.MovieID
group by all
having count(*) > 1000
order by avg_rating desc
limit 20
) TO ‚top20.csv‘ (HEADER, DELIMITER ‚;‘);
- cat top20.csv
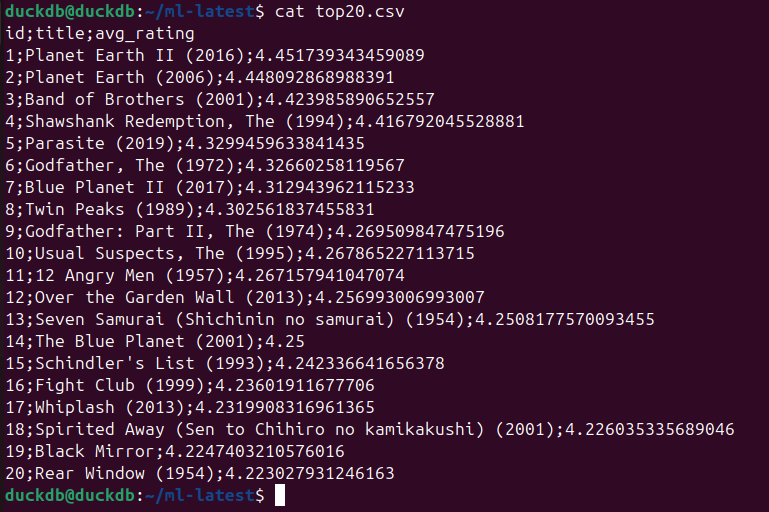
Export mit „,“ als Trennzeichen
Alternativ können wir auch „,“ als Trennzeichen verwenden,
Kapselungen (Quote Symbol) mit “ werden automatisch gemacht
COPY (
select row_number() OVER (order by avg(r.rating) desc) as id,m.title,avg(r.rating) as avg_rating
from movies.csv m join ratings.csv r on m.movieID=r.MovieID
group by all
having count(*) > 1000
order by avg_rating desc
limit 20
) TO ‚top20.csv‘ (HEADER, DELIMITER ‚,‘);
cat top20.csv
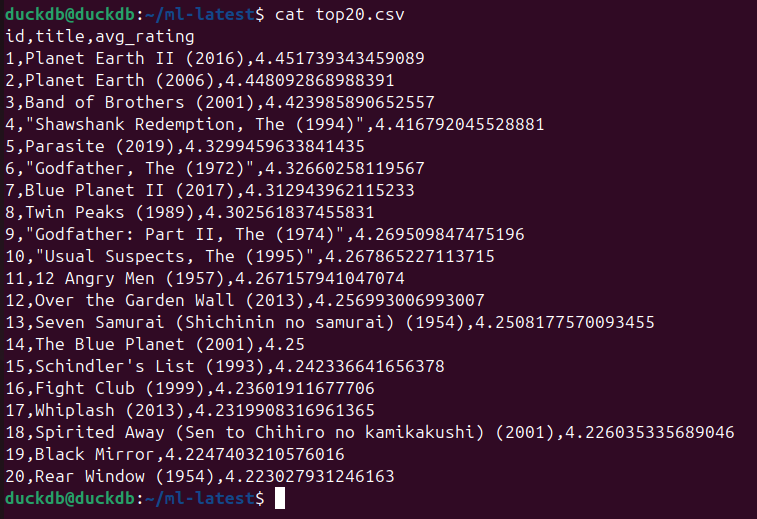
Fazit
Um unsere Dateien analysieren zu können, mussten wir die Daten nicht importieren, sondern konnten durch die serverlose Verwendung der DuckDB schnell unsere Textdateien (in unseren Fall .csv Dateien) analysieren und sogar Dateien joinen und Auswertungen auf diese machen.
Zusätzlich gibt es bei der SQL-Syntax noch ein paar nette Erleichterungen, wie zum Bespiel das von uns verwendete „group by all“ um nicht alle Felder einzeln angeben zu müssen, die gruppiert werden sollen.
Ergebnisse lassen sich ebenfalls einfach, schnell und unkompliziert in Dateien exportieren und somit für weitere Zwecke verwenden.
Wir können die Auswertungen auch in .db Dateien hinterlegen und diese dann an andere Stellen zur Verarbeitung weiterleiten.