
Viele Unternehmen stehen vor dem Problem, dass sie Auswertungen zu bestehenden Daten erstellen wollen und nicht wissen, wie die Umsetzung eines Systems aussehen kann.
In diesem Artikel wollen wir eines unserer Projekte vorstellen, bei dem wir ein automatisiertes Reporting auf einen Onlineshop aufgesetzt haben.
Aufgabenstellung
Ziel war es, aus einer Webseite und einem Webshop Daten zu Buchungen, Verkäufen und Kunden zu verarbeiten, zu bereinigen und zu visualisieren. Unser Partner hatte bisher alle Daten über mehrere Jahre nur in einem Excel aufgezeichnet. Zur Umsetzung brauchten wir aber eine sauberen Datenbasis.
Problemstellung
Die Herausforderungen des Projektes lauteten wie folgt:
- Zugriff auf die Daten des Webshops
- Aufbereiten der bestehenden Daten, die als Excel geführt wurden
- Überarbeiten der Eingabemasken auf der Webseite
Der Zugriff auf die Daten des Webshops zeigte sich als schwierig, da das verwendete E-Commerce Plugin externe Zugriffe nicht erlaubte.
Des Weiteren entpuppte sich das Aufbereiten der bestehenden Daten als sehr zeitaufwändig. Über mehrere Jahre hatten unterschiedliche Personen an einem Excel mit den Daten gearbeitet und dabei unterschiedliche Formate bei Datums- und Zahlfeldern verwendet.
Die Überarbeitung der Eingabemasken auf der Webseite war ebenfalls nötig. Die Masken davor hatten keine einheitliche Geburtstags- und Adressenformatierung. Ein weiterer Grund für unsaubere Daten.
Datenfluss
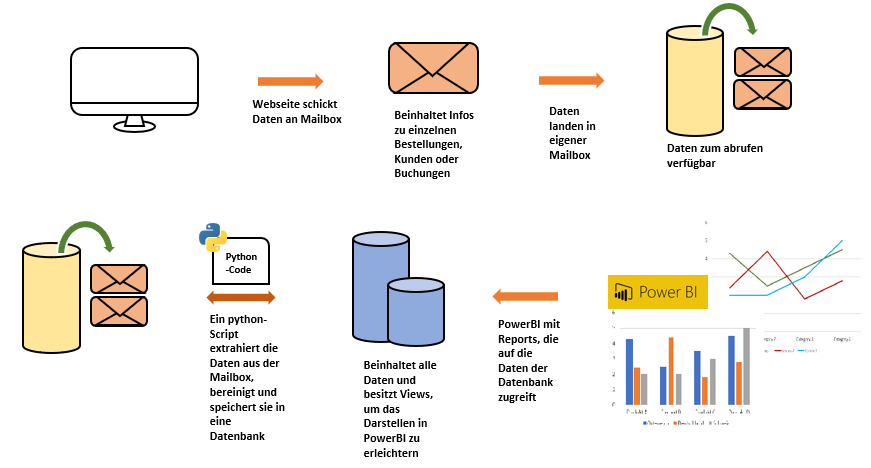
Da wir auf die Daten aus der WordPress-Datenbank keinen direkten Zugriff hatten, hat unser Kunde uns als „relay“ im Mailverteiler eingebaut. Unser Kunde hat jede Bestellung, Buchung und Kundenregistration per E-Mail erhalten, dadurch wurden uns die nötigen Daten ebenfalls zugesendet. Das folgende Diagramm zeigt, wie der Regelablauf des Datenflusses aussieht.
Umsetzung
Die Umsetzung setzte sich aus folgenden Punkten zusammen:
- Eingabeformulare auf der Kundenwebseite überarbeiten
- Aufbereiten der bestehenden Basisdaten
- Erstellen der Datenbank, der Tabellen und der Trigger.
- Erstellen des E-Mail-Verarbeiters
- Testen des ETL-Ablaufes
- Verbinden mit PowerBI, erstellen der Reports und Views
Gestartet haben wir, indem wir mit unserem Kunden die zukünftigen neuen Datenfelder und deren Formatierung auf der Webseite besprachen. Hierbei war es uns wichtig, dem Kunden verständlich darüber zu informieren, welche Auswirkungen unreine Daten im gesamten Wartungszyklus haben können.
Die Webmasken der Online-Eingaben waren unser nächstes Ziel. Ad hoc wollten wir wir ad hoc nur noch saubere Daten erhalten. Hierbei änderten wir das Feld des Geburtsdatums in einen date-picker, die Adresse erhielt einen location-picker und Telefonnummern durften nur noch mit Ländervorwahl eingegeben werden. Des Weiteren ernannten wir essenzielle Felder wie Vorname, Nachname, etc. zu Pflichtfeldern.
Anschließend setzten wir uns wieder mit unserem Kunden zusammen und besprachen die Aufbereitung der Bestandsdaten (Excel-Files). Parallel dazu bauten wir eine Datenbank mit den dazugehörigen Tabellen auf. Zusätzlich erstellten wir einige Trigger, die bei Änderungen in den Kundenstammdaten ab sofort die Kundentabellen aktualisieren und die Änderungen historisieren sollten.
Damit wir die Daten auch immer aktuell erhalten, erstellten wir ein Python-Programm, das die Daten aus unserer Projekt-Mailbox liest. Dies funktioniert, indem sich das Programm per SSL mit der Mailbox verbindet und alle E-Mails, die ungelesen sind, abruft und lokal auf einem Laufwerk abspeichert. Die ungelesenen E-Mails werden daraufhin als gelesen markiert. Das erneute Laden am nächsten Tag kann so verhindern werden. Zuletzt liest das Programm den Inhalt der E-Mails aus, fasst ihn in eine Liste und lädt diese in die Staging-Tabellen der Datenbank.
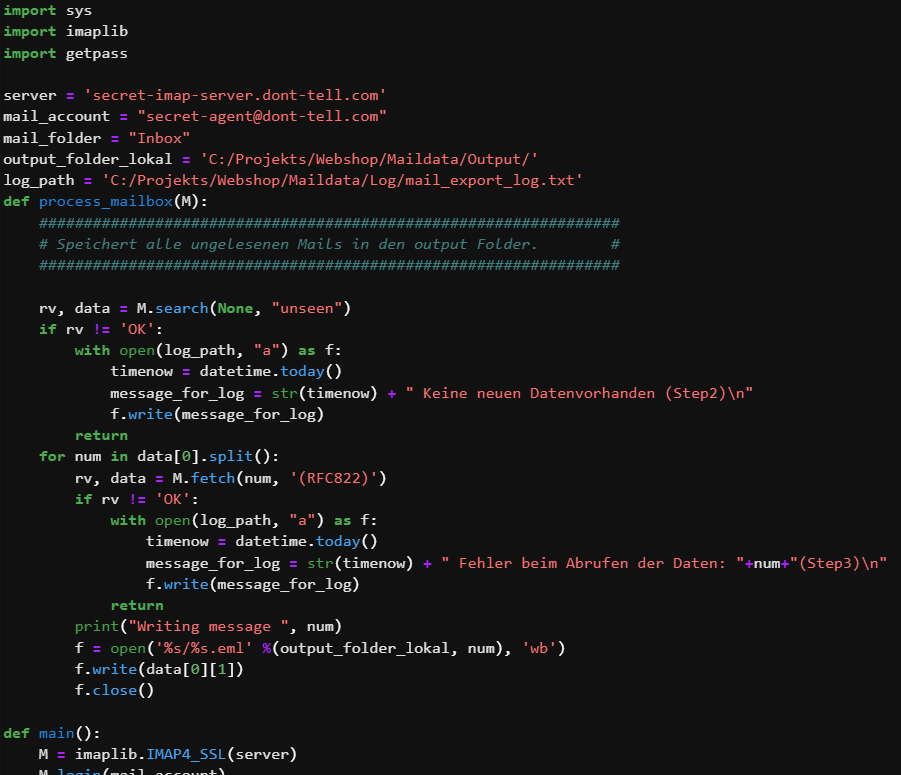
Nachdem Durchlauf des Python-Programms startet ein SSIS- Ablauf, der sich um das Einspielen der neuen Daten in die Datenbasis kümmert und den Vorgang in einer Log-Tabelle protokolliert. Dabei werden die Daten in den Importtabellen auf ihre Formatierung überprüft und in die Basis geladen. Daten, die nicht dem Erwartungswert entsprechen, werden in eine Fehler-Tabelle gespeichert. Änderungen von Kundendaten werden mittels Vorher-Nachher-Datensatz in eine Update-History gespeichert und so dokumentiert. Sollte beim Durchlaufen des Ablaufes etwas schief gehen, so wird dies von Error-E-Mails abgefangen. Diese beinhalten einen Fehlercode und die Text-Passage aus der Log-Tabelle. So werden wir über Fehlschläge immer sofort informiert und können rechtzeitig eingreifen.
Damit es beim Produktivstellen zu keinen Fehlern kommt, mussten wir nun den fertigen Ablauf testen. Dazu definierten wir mit bereits vorhandenen Daten ein Test-Set. Wir bauten auch Fehler ein, um den Ablauf auf alle möglichen Fehler-Szenarien zu Überprüfen. Nach dem Ausbessern von kleinen Fehlern und dem Einbauen von ein paar Typ-Konvertierungen war der Ablauf soweit betriebsfähig.
Das nächste Gespräch mit unserem Kunden startete auch schon, kurz nachdem wir das Testen abgeschlossen hatten. Thema war, welchen Reports dem Kunden zukünftig zur Verfügung gestellt werden sollten. Dieses Gespräch war insofern wichtig, da wir die Daten vorab schon in der Datenbank mittels Views zusammenschließen und filtern wollten. So sollte das Erstellen der PowerBI-Reports leichter fallen. Nach Freigabe der geplanten Views und Reports durch den Kunden, wurden diese von uns umgesetzt. Wir benötigten noch einen externen Zugang zur Datenbank und riefen die ersten Auswertungen über PowerBI ab. Zur Automatisierung des Ganzen (Daten abrufen bis zur Verarbeitung der Daten) erstellten wir eine Schedule, die sich um das Ausführen der Ablaufschritte kümmert.
Fazit
Dieses Projekt hat uns gezeigt, wie wir auch alternativ Daten eines Kunden verarbeiten können, und wie flexibel man Python zum Auslesen und Einspielen von Daten verwenden kann. Wie bereits in einem anderen Artikel (Einfache Arbeitsschritte ersparen mittels Python) berichtet, kann man mittels Python leicht einen ETL-Prozess unterstützen und Hürden beseitigen, an denen sonst eine Umsetzung scheitern könnte. Unseren Mitarbeitern hat es auch gezeigt, wie wichtig eine saubere Datenbasis für darauf aufsetzende Auswertungen ist.
Daher hier drei kleine Tipps für einen erfolgreichen ETL-Prozess:
- Auf saubere und gute Datenqualität achten
- Unnötige Attribute in der Datenbank vermeiden, um diese schlank zu halten
- Ein gutes Error-Handling per Log-Files, Tabellen und Benachrichtigungen sind die Basis für jedes schnelle Troubleshooting und erleichtern einem das Leben

