Datenquellen – Welche und woher?
Bevor man überhaupt mit dem Coding anfängt, ist es sinnvoll sich zu überlegen, welche Daten man überhaupt benötigt. Entwickelt man das Dashboard für eine Institution, so bekommt man die Daten meist von eben dieser. Ist dies allerdings nicht der Fall oder braucht man zusätzliche Daten, sollte man potentielle Datenquellen möglichst kritisch behandeln. Wie man Daten im Internet findet, sollte allgemein bekannt sein. Viel mehr steht die Vertrauenswürdigkeit der Daten und die benötigte Datenart im Vordergrund.
Hier eine kleine Checklist:
- Datenart – Welche
- statisch
- Sicherheit bzgl. Quelldatenänderungen in der Zukunft gewährleistet?
- dynamisch
- Wie oft benötigt man eine Aktualisierung und wie oft werden die Daten der Quelle aktualisiert?
- Wie oft ändert sich die Datenstruktur? Ist diese Änderung absehbar, kann man sich darauf vorbereiten? Wenn nicht; wie aufwändig ist eine manuelle Umstellung?
- statisch
- Datenquelle – Woher
- offizielle Daten sind vorzuziehen, da im Normalfall gewährleistet ist, dass sie überprüft wurden und die Quelle nicht einfach verschwindet.
- inoffizielle Daten müssen besonders unter die Lupe genommen werden, die Quelle kann auch ohne Vorwarnung verschwinden.
Betrachten wir die Datenquellen des Alpha ITC COVID-19 Dashboards:
Offizielle Datenquellen:
- Österreichische COVID-19 Daten: Bundesministerium für Gesundheit und Soziales, AGES-Website
- Globale COVID-19 Daten: John-Hopkins University Github repo
Die Vertrauenswürdigkeit der kritischen Dashboard-Informationen ist somit gewährleistet.
Aber was ist mit der Dynamik? Da die COVID-19 Situation datentechnisch noch Neuland ist, verändern sich die Datenstrukturen und betrachteten Daten leider manchmal unvorhergesehen. Hier muss man beim Coden kompensieren, indem man den Code der ETL-Prozesse (extract, transform, load) möglichst allgemein und flexibel hält, um eine einfache Umstellung zu gewährleisten.
Inoffizielle Datenquellen:
- Österreichische Bundeslandgrenzen: GeoJSON/TopoJSON Austria (2016-2021) Github repo
Dieses repo bezieht Daten aus und modifiziert Daten des Open-Data Portals der Statistik Austria. Es ist also inoffiziell, aber mit einer vertrauenswürdigen Datengrundlage. Des Weiteren können die Daten als statisch behandelt werden. Bundeslandgrenzen ändern sich ja bekanntlich im Normalfall nicht.
Datenqualität – Wie gut?
Selbstverständlich muss man die Daten der Quellen auch auf Qualität und Fehler überprüfen.
3 Fragen stehen im Vordergrund:
- Sind die Daten vollständig?
- Sind die Daten fehlerhaft?
- Genügen die Daten den Anforderungen?
Frage 3 ist natürlich vom gewählten Thema und den Anforderungen auf Detailreichtum abhängig. Fragen 1 und 2 sind jedoch essentiell und müssen in jedem Projekt beantwortet werden.
Besonderes Augenmerk sollte daraufgelegt werden, dass auch offizielle Quellen unvollständige oder fehlerhafte Daten enthalten können.
Als Beispiel seien hier die John-Hopkins Globalen COVID-19 Daten angeführt. Es kann passieren, dass manche Länder fehlerhafte oder unvollständige Daten übermitteln.
Betrachten wir die Daten der Türkei:
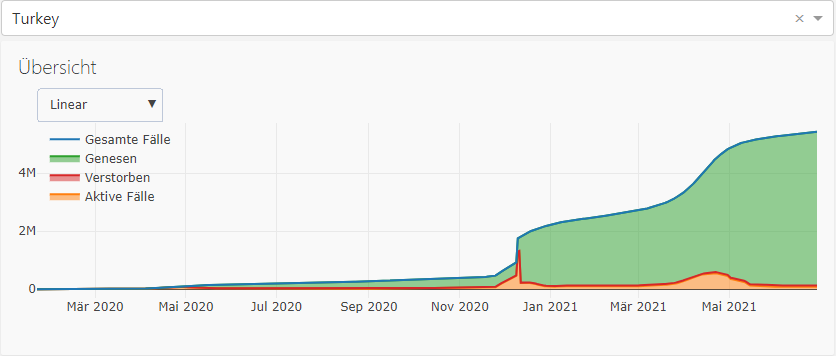
Hier kann man leicht sehen, dass im Dezember 2020 eine Anomalie besteht. Es kann sein, dass die Daten vorher nicht anständig gemeldet wurden oder dass nur an diesen Tagen Falschmeldungen waren.
Die Aufgabe des Data Scientist ist es in diesem Fall, explorative Untersuchungen in den Daten durchzuführen, Anomalien und Fehler zu erkennen und wenn möglich, zu korrigieren.
Als Beispiel für unvollständige Daten betrachten wir Genesene in den USA:
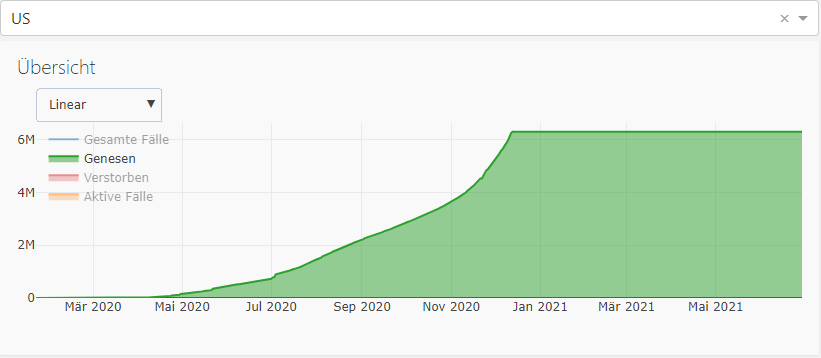
Es ist höchst unwahrscheinlich, dass seit Dezember 2020 keine einzige Person mehr genesen ist. Es wurde die Zahl der gesamt Genesenen in den Daten sogar auf 0 gesetzt. Dies musste für das Dashboard manuell korrigiert werden, um die Statistik nicht mehr als nötig zu verzerren.
Datenextraktion – Wie und wohin?
Nachdem man die Quellen gesammelt und überprüft hat, beginnt die Überlegung über die Methode der Extraktion und eine optionale, lokale Speicherung.
Folgendes ist zu beachten:
- Wie groß ist die Datenmenge?
- Wie stark müssen die Daten transformiert werden?
Beides beeinflusst sowohl die Performance als auch die Methodik.
Bei kleinen Datenmengen, die man quasi ad-hoc in das Dashboard übernehmen kann, weil sie z.B. im json-Format sind, bietet sich eine direkte Verbindung über eine Schnittstelle (z.B. ein Web-Service) an, die periodisch aktualisiert wird.
Doch was ist mit großen Datenmengen, die stark transformiert und evtl. auch fehlerbereinigt werden müssen? Dann bieten sich auf jeden Fall eine Datenbank zur Speicherung und ein komplexer ETL-Prozess in einer höheren Programmiersprache an. Man verliert Flexibilität aber gewinnt Performance! Den Verlust an Flexibilität kann man jedoch teilweise mit sauberer und vorausschauender Programmierarbeit kompensieren.
Ein Spezialfall, am Beispiel der Twitter-Stimmungsdaten des Dashboards, sei hier noch angeführt:
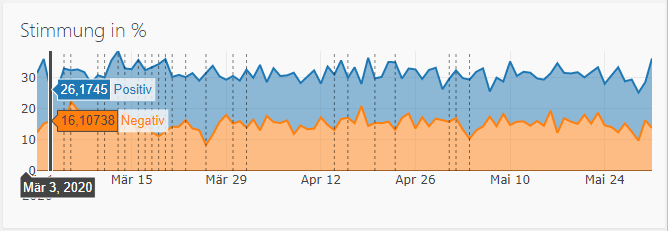
Hier hat man sowohl große Datenmengen als auch eine komplizierte und zeitlich langwierige Extraktion über ein spezielles Python Package. Ein Voraus- oder Parallelladen der Rohdaten in eine Datenbank ist nötig, um den Betrieb des Dashboards nicht zu stören. Im Optimalfall kann man durch Begrenzen der Daten (z.B. auf Region oder Datum) die Performance steigern. Man verliert aber oft die Möglichkeit, aktuellste Daten darzustellen.
Viel Erfolg bei Ihrem nächsten Projekt.

