
Wer kennt es nicht? Im Office-Bereich fallen oft einfache Arbeiten an, bei denen man sich denkt: „Kann man das nicht mit einem Programm automatisieren?“ Mit Python lassen sich beispielsweise Arbeiten automatisieren, die Word oder Excel-Dateien aufbereiten und in eine Datenbank speichern.
Wenn man ein paar wenige Voraussetzungen beachtet, lassen sich solche Vorhaben leicht umsetzen:
- Die Inhalte der zu verarbeiteten Dateien müssen einen gleichen Aufbau besitzen.
- Inhalte wie Datumswerte müssen im selben Format gespeichert werden.
- Die Datenbank muss vom Python-Script aus erreichbar sein.
- Zum Automatisieren braucht man einen Server, der das Programm automatisch ausführt.
- Auf dem Computer, auf dem das Programm schlussendlich laufen soll, muss Python installiert sein.
Was ist Python?
Python ist eine Programmiersprache, die durch ihren einfachen Aufbau leicht lesbar und gut verständlich ist. Somit lassen sich Aufgaben rasch umsetzen. Python entwickelt sich weltweit rasant. Das betrifft sowohl den Bekanntheitsgrad als auch die Weiterentwicklung dieser Programmiersprache. Den Verwendungsmöglichkeiten sind (fast) keine Grenzen gesetzt. Sie wird u. A. von Mathematikern, Forschern und Data Analysten bevorzugt. Die Programmiersprache ist leicht zu lernen, und man kann mit wenig Know-How nützliche Programme schreiben. Python eignet sich perfekt, um langweilige und wiederholende Arbeiten zu automatisieren. Man muss kein Programmierer sein, um Python verwenden zu können. Die Syntax ist leicht verständlich und eine große Community unterstützt bei Fragen und Problemen. Lassen Sie mich anhand eines Beispiels die einfache Umsetzung zeigen.
Fallbeispiel: Arzt-Befunde
Angenommen wir erhalten täglich Befunde von Patientenuntersuchungen, die von Ärzten in Formularen eingegeben wurden Wir sammeln diese Befunde in einem Ordner Namens „Befunde“. Die Inhalte dieser Formulare werden von einem Programm ausgelesen, in Excel-Dateien gespeichert und beinhalten folgenden Text mit gleichem Aufbau:
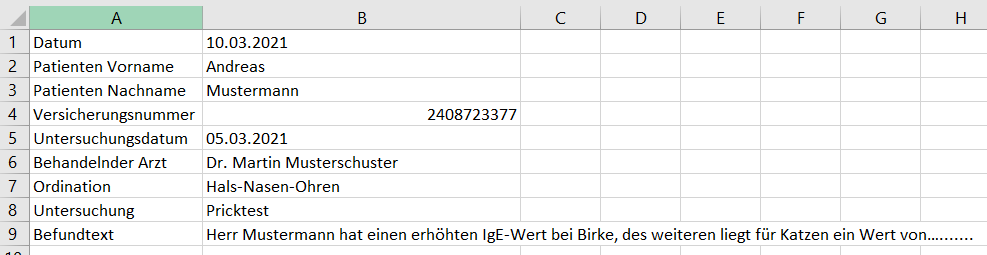
Wichtig: Die Struktur wie Reihenfolge und Formatierung der Felder bleiben immer gleich. Das heißt, dass zum Beispiel das Ordinations-Feld immer an der siebten Stelle steht und das Datum immer gleich formatiert sein muss.
Wie haben wir diese Aufgabe gelöst?
Umsetzung – Textverarbeitung
In Python deklarieren wir den Ordnerpfad, in denen sich die Befunde befinden. Anschließend erstellen wir eine Liste, in der wir die Namen der Befunde speichern und dann auslesen.
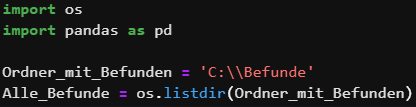
Dafür erstellen wir eine Schleife, die den Inhalt der Befunde ebenfalls in eine Liste schreibt.
Nachdem wir die Inhalte der Befunde in Listen eingelesen haben, könnten wir an diesen Punkt die Daten noch aufbereiten. Um möglichste viele Fehler und weitere Arbeit in der Zukunft zu vermeiden, sollte das Formular, mit dem die Befunde erstellt werden, die Eingabe schon so gut einschränken, dass wir uns beim Einlesen Aufbereitungsarbeiten sparen.
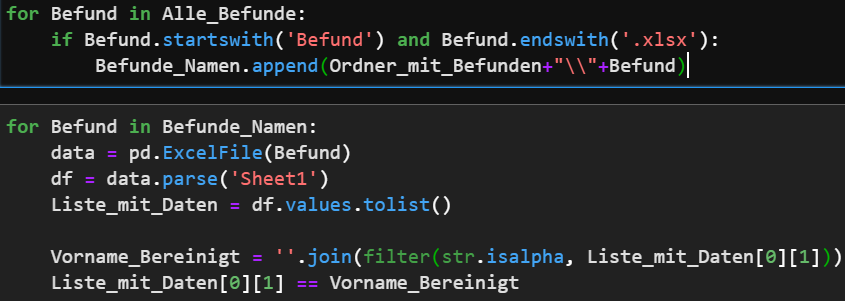
Da dies nicht immer der Falls ist, werden wir in diesem Beispiel das Feld Patienten Vorname aufbereiten. Da auch ein Arzt einmal einen Fehler machen kann, wollen wir überprüfen, ob sich in dem Feld Vorname auch wirklich nur Buchstaben und keine Zahlen oder Sonderzeichen befinden.
Umsetzung – Speicherung in SQL-Server
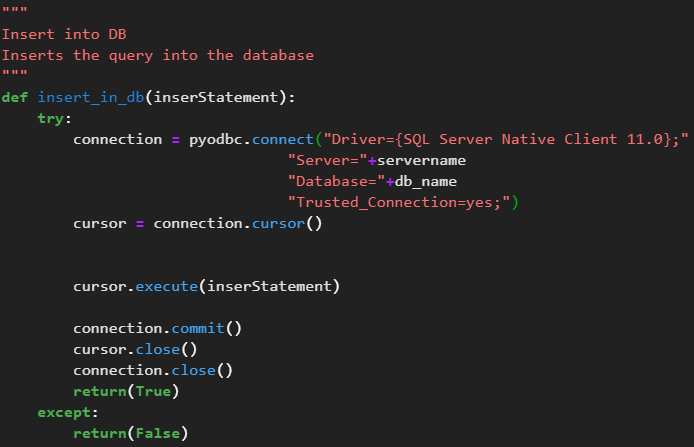
Nachdem wir nun mit der Qualität unserer Daten zufrieden sind, wollen wir diese auch automatisch in unsere SQL-Server Datenbank speichern.
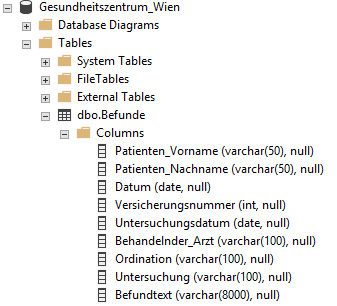
Dafür haben wir eine Datenbank mit den Namen „Gesundheitszentrum Wien“. Unsere Befunde wollen wir in die Tabelle Befunde speichern.
In Python führen wir für jeden Befund ein Insert-Statement aus, das uns die Daten in die Datenbank speichert. Dafür rufen wir die function „insert_in_db“ auf und übergeben das generierte Insert Statement, das die Daten zu dem Befund beinhaltet.
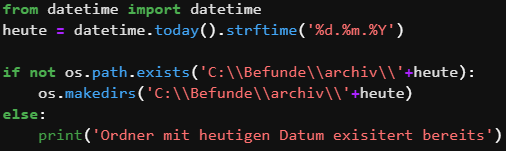
Nachdem nun alle Befunde in die Datenbank gespeichert wurden, archivieren wir die Dateien indem wir sie in einen Unterordner zu dem heutigen Tag in den Ordner namens Archiv verschieben. Dafür überprüfen wir, ob es im Archiv Ordner schon einen Ordner mit dem heutigen Datum gibt.
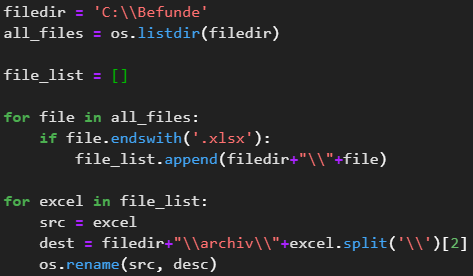
Daraufhin werden die Befunde archiviert.
Nach dem Testen unseres Programmes speichern wir dieses auf unseren Server und erstellen einen Zeitplan, der das Programm automatisch jeden Tag um 22:00 am Abend laufen lässt, damit die Befunde am nächsten Tag schon in der Datenbank zur Verfügung stehen.

Weitere Verarbeitungsbeispiele
Wie in unserem Beispiel gezeigt, lassen sich auch Emails aus Mailboxen automatisch abarbeiten. Hierzu wird mit einer Email-Library (vorgefertigter Code) eine Verbindung zu einer Outlook Mailbox erstellt, die alle Emails aus einer bestimmten Mailbox ausliest, die noch nicht als gelesen markiert sind und lädt diese anschließend herunter. Zusätzlich kann man aus diesen Emails auch die Anhänge extrahieren und ebenfalls weiterverarbeiten.
Ebenfalls kann man PDF’s, die zum Beispiel Rechnungen aus der Buchhaltung darstellen und für die Buchhaltung verarbeitet gehören, zu Text umwandeln und diesen anschließend aufbereitet in ein CRM System zu laden.
Die goldene Regel hierbei lautet immer: Die Struktur der Dateien muss gleich sein!
Sollte das nicht der Fall sein, muss die Struktur in einem Vorverarbeitungs-Schritt angeglichen werden.
Fazit
Mit Python lassen sich viele leichte/kleine Arbeiten automatisiert erledigen. Soll es das Weiterverarbeiten von Textdateien, das Updaten von Personaldaten oder das Auslesen von Emails oder PDF’s sein – mit Python lässt sich in wenig Zeit eine Lösung finden. Das Wichtigste hierbei ist immer die Struktur der Daten, die homogen sein muss. Aber falls es mal zu einem Fehlschlag kommt, ist das auch kein Problem. Mit wenig Aufwand können zum Beispiel Emailbenachrichtigungen mit den Fehlertexten verschickt und die fehlerhaften Dateien in einen Ordner zum Kontrollieren verschoben werden.
Auch das Error Handling in Python kann rasch und einfach individuell gestaltet werden.

