
In diesem Blogartikel wollen wir euch zeigen, wie man mittels Microsoft SQL Server Integration Services (SSIS) auf einem SQL-Server und mit Python oder C# einen zeitgesteuerten Ablauf erstellen kann. In unserem Fallbeispiel haben wir ein Python-Skript, das über einen FTP-Server Wetterdaten in Form eines CSV-Files herunterlädt. Diese Files sollen anschließend in unserer SQL-Server Datenbank landen und archiviert werden. Die Wetterdaten werden stündlich aktualisiert, daher muss unser gesamter Ablauf jede Stunde ausgeführt werden.
Das Python-Skript fragt per urllib den FTP-Server nach den neuen Files. Diese werden in einen Ordner mit dem heutigen Datum importiert. Das Programm überprüft hierbei, ob der Ordner bereits vorhanden ist. Wenn dies nicht der Fall ist, legt das Programm den Ordner an.
In unserem SQL-Server haben wir jeweils zwei Tabellen für die Wetterdaten erstellt. Einmal eine Wetterdaten-Basis Tabelle und einmal eine Wetterdaten-Import Tabelle. Die Import Tabelle brauchen wir, weil wir kleine Bereinigungen an den Daten vornehmen wollen. Als Beispiel: Vor dem Import in die Basis Tabelle aktualisieren wir das Feld Windspitzen, da im File für Messungen von 0.0 der Text „Windstille“ eingetragen wurde, wir aber gerne 0.0 als Wert haben möchten.
Darauf folgt dann auch schon eine Archivierung, wo bei einem erfolgreichen Durchlauf die Daten in ein Archiv geladen werden. Tritt ein Fehler auf, legt das Programm die Daten in einen Sicherungsorder ab, damit die Daten beim nächsten Durchlauf nicht verloren gehen und der Fall im Detail ansehen werden kann. Des Weiteren wird im Falle eines Fehlschlages ein E-Mail zur Information versendet.
SSIS-Package erstellen
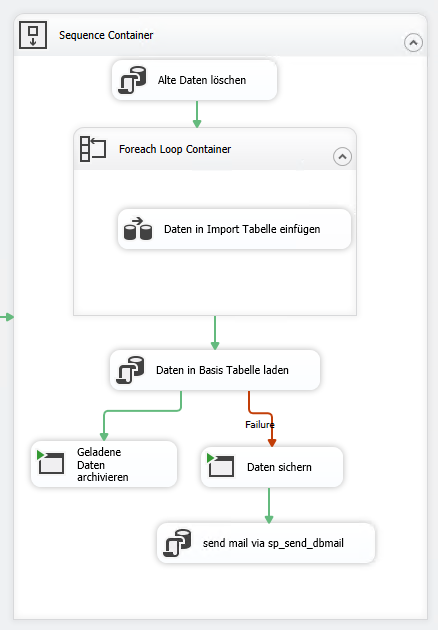
Der SSIS-Ablauf sieht daher wie folgend aus:
Die Variablen sind wie folgt:

Die einzelnen Arbeitsschritte befinden sich in einem Sequence-Container.
Im ersten Schritt wird die Import Tabelle truncated, da sie nur als Zwischenspeicher dient. Dies erfolgt in der Form eines Execute SQL Tasks.
Im darauffolgenden Schritt wird in einem Foreach Loop Container jedes File einzeln in die Import Tabelle geladen. Der Container hat in den Einstellungen unter „Collection“ als Enumerator „Foreach File enumerator“ eigetragen. Bei dem Folder Pfad befindet sich der Ordner, in den unser Python-Skript unsere CSV-Files abspeichert. In dem Feld Files gehört *.csv eigetragen, da wir wollen, dass jedes File verarbeitet wird. Danach müssen wir in den Reiter Variable Mappings wechseln.
Hier verwenden wir eine unserer Variablen: User::CurrentFile
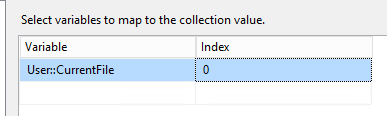
Dadurch wird bei jedem Durchlauf der Schleife, das File, über das die Schleife gerade iteriert, in die Variable gespeichert.
Der Task im Foreach Loop Container, der für das tatsächliche Laden der Daten bestimmt ist, heißt „Daten in Import Tabellen einfügen“ und ist ein „Data Flow Task“.
Im Data Flow Task befinden sich zwei weitere Tasks, ein Flate File Source Task zum Laden der Datei, die unser Python-Skript heruntergeladen hat und das sich derzeit in der CurrentFile Variable befindet und der zweite Task „OLE DB Destination“ für das Importieren in die Import Datenbank.
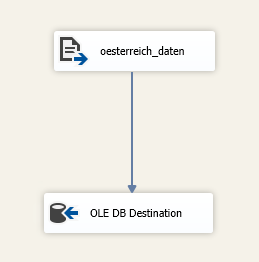
Der Flat File Source Task braucht einen Flat File Source Connection Manager. Dieser Connection Manager braucht von uns dynamisch die Info, welches File er importieren soll. Dies gelingt nur mittels Expressions. Expressions sind dynamische Werte, die für Einstellungen übernommen werden. Bei unserer Flat File Source können wir bei dem Feld „File Path“ statisch einen Pfad zu einem File angeben. Da wir aber über mehrere Files iterieren wollen, muss sich dieser File Path auch dynamisch immer an das nächste File anpassen. Daher setzen wir im Expression Builder für den File Path folgende Expression:
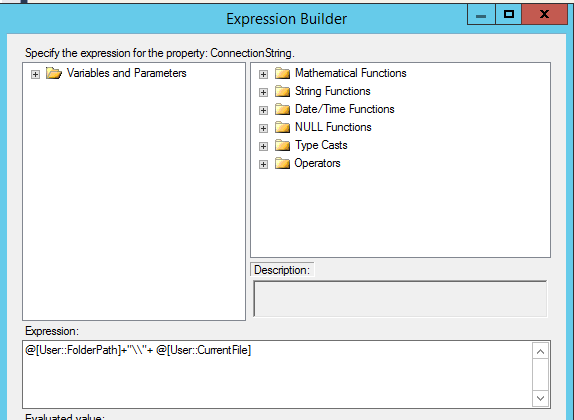
In der Variable FolderPath steht unser Pfad zu dem Ordner, in dem sich unsere Daten-Files befinden. CurrenFile wird von dem ForLoop Container befüllt. Daraus ergibt sich bei jedem Durchlauf der Pfad zum nächsten File.
Der OLE DB Destination Task braucht einen OLE DB Connection Manager. Dieser beinhaltet die Server Infos zu unserer SQL-Server Datenbank. Dann müssen wir nur noch unsere Import Tabelle angeben und das Mapping erstellen. Im Mapping geben wir an, welche Felder aus dem File welchen Feldern aus der Datenbank-Tabelle entsprechen.
Nachdem nun der ForLoop Container durchgelaufen ist und die Daten von all unseren Files sich in der Import Datenbank befinden, müssen die Daten noch aktualisiert und in die Basis Tabelle geladen werden. Zu Beginn meiner Entwicklertätigkeit von SSIS Packages fand ich es gut, wenn Packages schlank und klein waren. Deswegen befindet sich in diesem Beispiel das Update auf den Import Tabellen und das Einspielen in die Basis in einem einzelnen SQL-Skript.
Nach nun mehreren Jahren Erfahrung würde ich diese beiden Schritte auf zwei SQL-Skripte aufteilen. Dies dient nicht nur zur besseren Übersicht über jeden einzelnen Schritt, der im Package passiert, sondern auch zur Fehleranalyse. Wenn das Package in diesem Zustand bei dem Skript Task für den Basis Import abstürzen würde und ich dazu ein E-Mail erhalten würde, dann wüsste ich noch gar nicht, ob etwas bei einem Update gescheitert ist oder ob der Insert fehlgeschlagen ist. Daher sollte man sich selbst einen Gefallen tun und die Schritte so gut wie möglich aufteilen, damit einem selbst oder einem Kollegen das Nachvollziehen und eventuelle Troubleshooten leichter fällt.
Um den Ablauf aber jetzt nicht anzugreifen, erfolgt das Update und das Insert in einem einzelnen SQL-Skript. Dazu brauchen wir wieder einen SQL-Skript Task und ein SQL-Skript, indem unser Update und Insert Code gespeichert ist. In den SQL-Skript Task hängen wir den Pfad zu unserem SQL-Skript ein. Im SQL-Task Editor folgen noch ein paar Einstellungen. Der Connection Type im SQL Statement Menü muss auf OLE DB + unserem OLE DB Connection Manager geändert werden. SQL-SourceType gehört auf FileConnection umgestellt. Darunter müssen wir dann gleich die Flat File Connection zu unserem SQL-Skript einhängen.
Die nächsten beiden und fast letzen Schritte, hängen vom Ergebnis des „In die Basis laden“ Steps ab. Je nachdem ob dies erfolgreich oder fehlgeschlagen ist, müssen wir die Files verschieben. Bei einem Erfolg werden die Daten in ein Archiv geladen. Bei einem Fehlschlag werden die Files in einen Sicherungs-Ordner geladen. Für beide Szenarien brauchen wir ein Skript, dass uns die Files wegkopiert. Hierfür haben wir zwei Powershell-Skripts erstellt, die die Files aus unserem Ordner auslesen und in einen Zielordner kopieren.
Bei einem erfolgreichen Durchlaufen endet hier das SSIS-Package. Wenn der Durchlauf aber fehlgeschlagen ist, wird noch über den SQL-Server ein Error-E-Mail versendet. Dies geschieht ebenfalls über die SQL-Server Verbindung. Hierbei haben wir aber kein SQL-Skript, dass wir per File Manager verbinden, sondern wir machen dies über die „Direct Input“ Methode.
Das SQL-Statement sendet über die sp_send_dbmail Funktion ein E-Mail mit einen Hinweis an die gewünschten Empfänger.
Hiermit wäre das SSIS-Packet fertig.
Job einrichten
Jetzt müssen wir nur noch dafür sorgen, dass unser Ablauf auch jede Stunde automatisch ausgeführt wird. Dies erfolgt im Microsoft SQL Server Management Studio. Hier müssen wir uns mit unserer SQL-Instanz verbinden und dann zum SQL Server Agent navigieren. Im Reiter Jobs finden wir alle erstellten Jobs. Inaktive Jobs lassen sich durch ein rotes X im Icon erkennen. Wenn wir jetzt einen Rechtsklick auf Jobs machen, dann können wir einen neuen Job erstellen. Nach der Namensvergabe können wir in den Reiter „Steps“ wechseln und unsere Arbeitsschritte einbauen.
Zuerst muss unser Python Skript laufen und unsere Daten herunterladen. Daher klicken wir unten auf den Button „New“, geben dem Step einen Namen und wählen bei Type „Operating system (cmdExec)“ aus. „Run as“ entspricht dem SQL-Server User, mit dessen Rechten dieser Step ausgeführt werden soll. Hier vergebe ich meinen User, der die benötigten Rechte im SQL-Management Studio sowie auf dem Windows Gerät hat. Im Fenster „Command“ kommt jetzt noch der Pfad zu der Python-exe, gefolgt von dem Pfad zum Python-Skript. Das Ganze wird dann vom Server Agent wie ein cmd-Befehl ausgeführt.
Als zweiten Step benötigen wir nun das SSIS-Package. Hierfür erstellen wir einen Step mit dem Typ „SQL Server Integration Services Package“. Der „Runs as“ User ist derselbe wie beim Step davor. Package Source -> File System und unten bei Package geben wir den Pfad zu unserem SSIS-Package an.
Somit sind alle Arbeitsschritte in unserem Job angelegt. Als nächstes müssen wir aber noch eine Laufzeit einrichten. Hierfür wechseln wir in den Schedules-Reiter und klicken wieder auf „New“. Anbei ein Screenshot, damit der Job jeden Tag und jede Stunde ausgeführt wird:
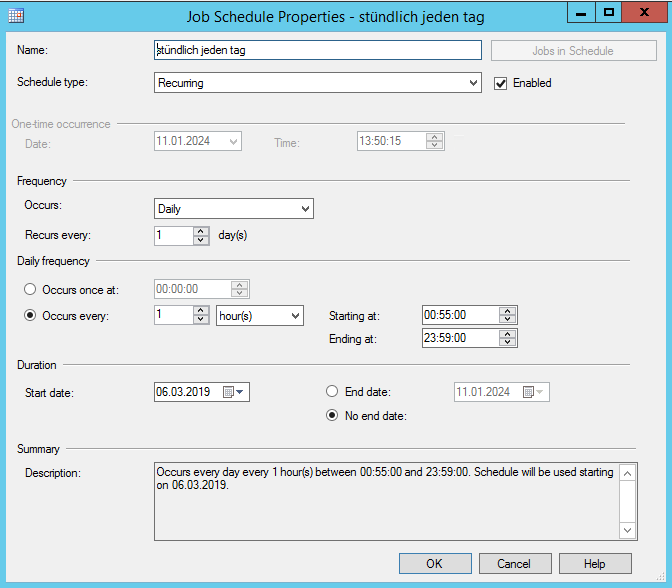
Das Wichtigste hier ist der Haken bei der Enabled Box.
Somit ist der Ablauf fertig und wird von nun an stündlich ausgeführt.
In einem weiteren Artikel werde ich dieses alte Projekt im Detail durchgehen und schaue, was bei diesem Ablauf nicht gut gelöst ist und wie er verbessert werden kann.

