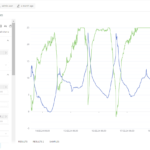
Was kennen wir, was haben wir?
- Wir haben bisher einen Hadoop Cluster, Apache Doris und Superset installiert
https://www.bi4you.org/artikel/hadoop-cluster-testinstallation/
https://www.bi4you.org/artikel/apache-doris-installation/
https://www.bi4you.org/artikel/visualisierung-von-daten-mit-superset/ - Unsere Wetterdaten landen weiterhin in unserer MariaDB
https://www.bi4you.org/artikel/diy-mini-bigdata-hygrometer-part-1/
https://www.bi4you.org/artikel/diy-mini-bigdata-hygrometer-part-2/ - Zusätzliche haben wir unsere Wärmepumpendaten ebenfalls in unserer MariaDB gespeichert und in Superset ein Dashboard erstellt
https://www.bi4you.org/artikel/waermepumpendaten-mit-superset/
Was ist jetzt geplant?
Da wir mittlerweile unterschiedliche nützliche Tools kennen gelernt haben, können wir unser Wissen (und Anleitungen) nutzen und alles kombinieren – dazu verwenden wir 3 Raspberry Pi’s:
- 1x Pi5b 8GB (Master) und 2x Pi4b 4GB (Worker)
- 3x 128GB MicroSD Karten
Umsetzen werden wir:
- Raspberry Pi OS installieren und einrichten
- Installation Hadoop Cluster
- Installation Doris Cluster
- Synchronisieren der MariaDB Daten in unsere DorisDB
- Installation Superset
- Übernahme der vorhandenen Superset Dashboards + Anpassungen
Raspberry Pi OS installieren und einrichten
Die Installation erfolgt mit dem Pi Imager https://www.raspberrypi.com/software/
auf 128GB MicroSD Karten.
Verwenden werden wir die 64bit Lite Version von Bookworm (eine ältere Version gibt es für den Pi5 nicht)
Wir können nach der Installation die Schreib- und Lesegeschwindigkeit der SD Karten mit testen:
dd if=/dev/zero of=./TestingFile bs=100M count=10 oflag=direct && dd if=./TestingFile of=/dev/zero bs=100M count=10 oflag=dsync && rm TestingFile
Der Pi 5 schafft 56MB/Sek schreibend und 93MB/Sek lesend.

Die Pi 4 schaffen etwas weniger, aber immerhin noch 32MB/Sek schreibend und 46MB/Sek lesend.


Für unsere Datenmengen reichen die Geschwindigkeiten vollkommen aus.
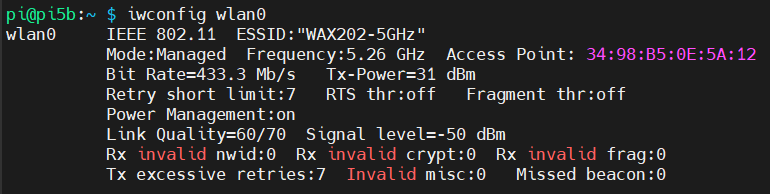
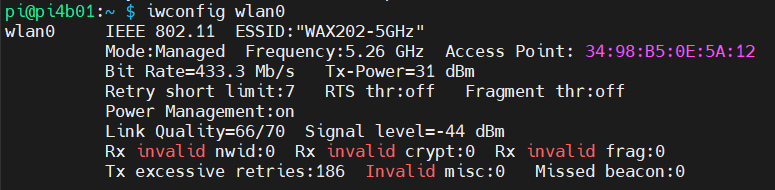
Unsere Netzwerkverbindung stellen wir mit unserem 5GHz WLAN her, die Geschwindigkeit beträgt hier 433Mbit und ist für unsere Zwecke ebenfalls ausreichend:
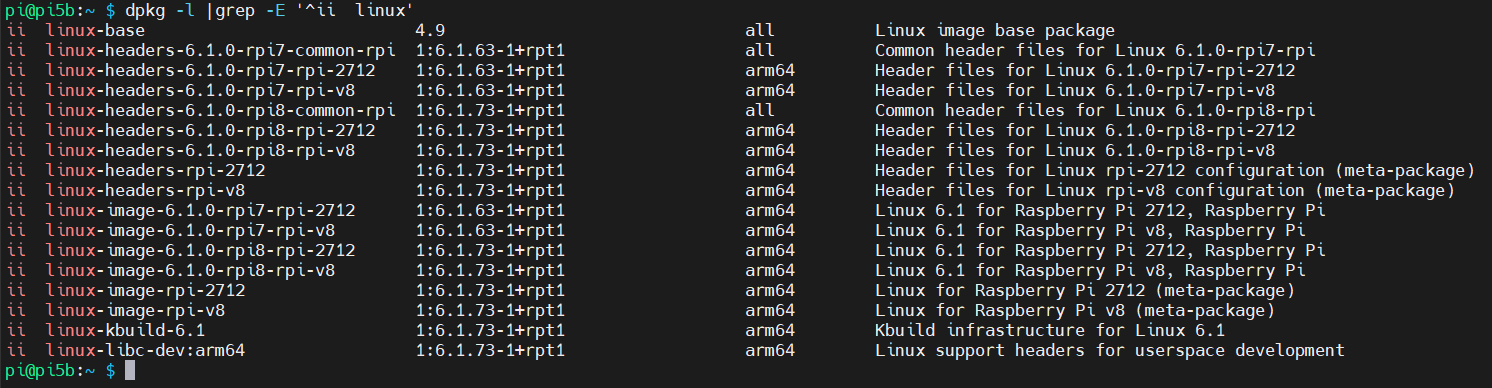
Unsere Raspberry Pi’s aktualisieren wir nach dem ersten Start mit
- sudo apt-get update && dist-upgrade
- sudo rpi-eeprom-update (für neue Firmware)
- rpi-update (für neuen Kernel) sollte nicht mehr benötigt werden, da dieser mittlerweile mit den apt Paketen mitkommt:
Journald-Size einschränken wir ein mit
- sudo vi /etc/systemd/journald.conf
SystemMaxUse=50M
- sudo journalctl –rotate
- sudo journalctl –vacuum-size=50M
Swap legen wir neu an (da sonst nur 100MB)
- sudo apt-get purge -y dphys-swapfile
- sudo apt-get install dphys-swapfile
ZRAM installieren und aktivieren wir ebenfalls
- sudo apt-get install zram-tools
- sudo systemctl enable zramswap
Installation Hadoop Cluster
Wir benötigen für die Verarbeitung unserer Wetter- und Wärmepumpendaten eigentlich keinen Hadoop Cluster, installieren ihn aber trotzdem falls wir später irgendwelche Sachen ausprobieren möchten. (z.B. Hadoop Tools sofern diese als aarch64 Pakete zur Verfügung stehen)
Hosts in /etc/hosts eintragen
- sudo vi /etc/hosts
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
#127.0.1.1 pi5b
192.168.42.33 pi5b
192.168.42.34 pi4b01
192.168.42.35 pi4b02
hduser anlegen
- sudo addgroup hadoop
- sudo adduser –ingroup hadoop hduser
- sudo usermod -aG sudo hduser
Java installieren
Mit der in Bookworm mitgelieferten Version 17 läuft Hadoop nicht, also werden wir JAVA 11 von Oracle verwenden und händisch installieren.
Der Download steht unter https://www.oracle.com/de/java/technologies/javase/jdk11-archive-downloads.html zur Verfügung.
- su – hduser
- sudo mkdir /opt/java
- sudo chown -R hduser:hadoop /opt/java
- tar -zxvf jdk-11.0.21_linux-aarch64_bin.tar.gz -C /opt/java
- sudo update-alternatives –install /usr/bin/java java /opt/java/jdk-11.0.21/bin/java 1
- java -version

- vi .profile
export JAVA_HOME=/opt/java/jdk-11.0.21
Hadoop Verzeichnisse anlegen
- sudo mkdir -p /data/hadoop/namenode
- sudo mkdir -p /data/hadoop/datanode
- sudo mkdir -p /data/hadoop/logs
- sudo chown -R hduser:hadoop /data/hadoop
- sudo chmod -R 775 /data/hadoop
- sudo chown -R hduser:hadoop /opt
- sudo chmod -R 775 /opt/
SSH-Keys verteilen
- ssh-keygen -t rsa -b 4096 -P „“
- ssh-copy-id hduser@pi5b
- ssh-copy-id hduser@pi4b01
- ssh-copy-id hduser@pi4b02
Hadoop installieren
Hadoop herunterladen und nach /opt entpacken
- wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6-aarch64.tar.gz
- tar xvpf hadoop-3.3.6-aarch64.tar.gz -C /opt/
- cd /opt/
- ln -s hadoop-3.3.6 hadoop
Hadoop Variablen setzen
- cd
- vi .profile
PATH=$PATH:/opt/hadoop/bin
PATH=$PATH:/opt/hadoop/sbin
export HADOOP_HOME=/opt/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=/data/hadoop/logs
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_OPTS=“-Djava.library.path=$HADOOP_HOME/lib/native“
export YARN_HOME=$HADOOP_HOME
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
export CLASSPATH=$CLASSPATH:/opt/hadoop/lib/*
export CLASSPATH=$CLASSPATH:/opt/hadoop/lib/native/*
- vi /opt/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/opt/java/jdk-11.0.21
export HADOOP_LOG_DIR=/data/hadoop/logs
- vi /opt/hadoop/etc/hadoop/mapred-env.sh
export HADOOP_LOG_DIR=/data/hadoop/logs
- vi /opt/hadoop/etc/hadoop/yarn-env.sh
export HADOOP_LOG_DIR=/data/hadoop/logs
Hadoop konfigurieren
- vi /opt/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://pi5b:9000</value>
</property>
</configuration>
- vi /opt/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hadoop/nameNode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop/dataNode</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions.superusergroup</name>
<value>hadoop</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>pi4b01:50090</value>
</property>
</configuration>
- vi /opt/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>341</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>682</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx272m</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx545m</value>
</property>
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>136</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop</value>
</property>
</configuration>
- vi /opt/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.acl.enable</name>
<value>0</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>pi5b</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2046</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2046</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>682</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>768</value>
</property>
<property>
<name>yarn.app.mapreduce.am.command-opts</name>
<value>-Xmx614m</value>
</property>
<property>
<name>yarn.timeline-service.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.timeline-service.hostname</name>
<value>pi5b</value>
</property>
<property>
<name>yarn.timeline-service.http-cross-origin.enabled</name>
<value>true</value>
</property>
<property>
<name> yarn.resourcemanager.system-metrics-publisher.enabled</name>
<value>true</value>
</property>
</configuration>
- vi /opt/hadoop/etc/hadoop/workers
pi4b01
pi4b02
.profile und Hadoop auf die anderen Hosts verteilen
- scp ~/.profile pi4b01:~/
- scp ~/.profile pi4b02:~/
- sudo apt-get install rsync
- rsync -aAvh /opt/*hadoop* pi4b01:/opt/
- rsync -aAvh /opt/*hadoop* pi4b02:/opt/
NameNode formatieren
- hdfs namenode -format
Hadoop Cluster starten mit
./start_hadoop.sh
Scriptinhalt von start_hadoop.sh
#!/bin/bash
# check for root -> its not allowed
if [ $EUID -eq 0 ] ; then
echo „This script cannot be run as root“
exit 1
fi
# check for running java processes
if [ $(jps |grep -v DorisFE |wc -l) -gt 1 ]
then
echo „java processes running, please check with jps and ps -ef…..“;
exit 1;
fi
echo „“
echo „##############################################################“
echo „starting hdfs…..“
echo „##############################################################“
/opt/hadoop/sbin/start-dfs.sh
echo -n „waiting for Safe mode is OFF…“;
x=1
while [[ $(hdfs dfsadmin -safemode get) == „Safe mode is ON“ ]]
do
echo -n „..“${x};
if [ ${x} -gt 14 ]
then
echo „“
echo „waited 60 seconds, exiting – please check hdfs safemode!“;
exit 1;
fi;
let x++;
sleep 4;
done
echo „“
echo „##############################################################“
echo „starting yarn + history server + timelineserver…..“
echo „##############################################################“
/opt/hadoop/sbin/start-yarn.sh
/opt/hadoop/bin/mapred –daemon start historyserver
/opt/hadoop/bin/yarn –daemon start timelineserver
echo „“
echo „##############################################################“
echo „cluster started, please check with jps…..“
echo „##############################################################“
Den Hadoop Cluster stoppen wir mit
./stop_hadoop.sh
Scriptinhalt von stop_hadoop.sh
#!/bin/bash
# check for root -> its not allowed
if [ $EUID -eq 0 ] ; then
echo „This script cannot be run as root“
exit 1
fi
# stop yarn
echo „“
echo „##########################################################################“
echo „stopping yarn + history server + timelineserver…..“
echo „##########################################################################“
/opt/hadoop/bin/yarn –daemon stop timelineserver
/opt/hadoop/bin/mapred –daemon stop historyserver
/opt/hadoop/sbin/stop-yarn.sh
# stop hdfs
echo „“
echo „##########################################################################“
echo „stopping hdfs…..“
echo „##########################################################################“
/opt/hadoop/sbin/stop-dfs.sh
echo „“
echo „##########################################################################“
echo „cluster stopped, please check with jps and ps -ef…..“
echo „##########################################################################“
Installation Doris Cluster
Doris herunterladen und Frontend installieren
- wget -c https://apache-doris-releases.oss-accelerate.aliyuncs.com/apache-doris-2.0.3-bin-arm64.tar.gz
- tar xpf apache-doris-2.0.3-bin-arm64.tar.gz
- cd apache-doris-2.0.3-bin-arm64/
- cp -r fe /opt/
- cd /opt/
- mv fe apache-doris-2.0.3_fe
- ln -s apache-doris-2.0.3_fe doris
- cd doris
- vi conf/fe.conf
CUR_DATE=`date +%Y%m%d-%H%M%S`
# the output dir of stderr and stdout
LOG_DIR = ${DORIS_HOME}/log
JAVA_OPTS=“-Djavax.security.auth.useSubjectCredsOnly=false -Xss4m -Xmx2048m -XX:+UseMembar -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=7 -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSClassUnloadingEnabled -XX:-CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -Xloggc:$DORIS_HOME/log/fe.gc.log.$CUR_DATE“
# For jdk 9+, this JAVA_OPTS will be used as default JVM options
JAVA_OPTS_FOR_JDK_9=“-Djavax.security.auth.useSubjectCredsOnly=false -Xss4m -Xmx2048m -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=7 -XX:+CMSClassUnloadingEnabled -XX:-CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -Xlog:gc*:$DORIS_HOME/log/fe.gc.log.$CUR_DATE:time“
##
## the lowercase properties are read by main program.
##
# INFO, WARN, ERROR, FATAL
sys_log_level = ERROR
# NORMAL, BRIEF, ASYNC
sys_log_mode = NORMAL
# store metadata, must be created before start FE.
# Default value is ${DORIS_HOME}/doris-meta
meta_dir = ${DORIS_HOME}/doris-meta
# Default dirs to put jdbc drivers,default value is ${DORIS_HOME}/jdbc_drivers
jdbc_drivers_dir = ${DORIS_HOME}/jdbc_drivers
http_port = 9080
rpc_port = 9020
query_port = 9030
edit_log_port = 9010
# Choose one if there are more than one ip except loopback address.
# Note that there should at most one ip match this list.
# If no ip match this rule, will choose one randomly.
# use CIDR format, e.g. 10.10.10.0/24 or IP format, e.g. 10.10.10.1
# Default value is empty.
# priority_networks = 10.10.10.0/24;192.168.0.0/16
priority_networks = 192.168.42.0/24
# Advanced configurations
# log_roll_size_mb = 1024
sys_log_dir = ${DORIS_HOME}/log
# sys_log_roll_num = 10
# sys_log_verbose_modules = org.apache.doris
# audit_log_dir = ${DORIS_HOME}/log
# audit_log_modules = slow_query, query
# audit_log_roll_num = 10
# meta_delay_toleration_second = 10
# qe_max_connection = 1024
# qe_query_timeout_second = 300
# qe_slow_log_ms = 5000
- cd
- vi .profile
export DORIS_HOME=/opt/doris
- scp ~/.profile hduser@pi4b01:~/
- scp ~/.profile hduser@pi4b02:~/
- sudo apt-get install mariadb-client
- sudo vi /etc/security/limits.conf
hduser soft nproc 65536
hduser hard nproc 65536
hduser soft nofile 65536
hduser hard nofile 65536
- sudo vi /etc/sysctl.conf
vm.max_map_count=2000000
Frontend starten und Backends hinzufügen
- /opt/doris/bin/start_fe.sh —daemon
- sudo apt-get install mariadb-client
- mysql -h pi5b -P 9030 -uroot
ALTER SYSTEM ADD BACKEND „pi4b01:9050“;
ALTER SYSTEM ADD BACKEND „pi4b02:9050“;
Backends installieren
- cd ~/apache-doris-2.0.3-bin-arm64/
- rsync -aAvh be pi4b01:/opt/
- rsync -aAvh be pi4b02:/opt/
Tätigkeiten auf pi4b01/pi4b02
- cd /opt/
- mv be apache-doris-2.0.3_be
- ln -s apache-doris-2.0.3_be doris
- vi /opt/doris/conf/be.conf
CUR_DATE=`date +%Y%m%d-%H%M%S`
PPROF_TMPDIR=“$DORIS_HOME/log/“
JAVA_OPTS=“-Xmx1024m -DlogPath=$DORIS_HOME/log/jni.log -Xloggc:$DORIS_HOME/log/be.gc.log.$CUR_DATE -Djavax.security.auth.useSubjectCredsOnly=false -Dsun.java.command=DorisBE -XX:-CriticalJNINatives -DJDBC_MIN_POOL=1 -DJDBC_MAX_POOL=100 -DJDBC_MAX_IDLE_TIME=300000 -DJDBC_MAX_WAIT_TIME=5000″
# For jdk 9+, this JAVA_OPTS will be used as default JVM options
JAVA_OPTS_FOR_JDK_9=“-Xmx1024m -DlogPath=$DORIS_HOME/log/jni.log -Xlog:gc:$DORIS_HOME/log/be.gc.log.$CUR_DATE -Djavax.security.auth.useSubjectCredsOnly=false -Dsun.java.command=DorisBE -XX:-CriticalJNINatives -DJDBC_MIN_POOL=1 -DJDBC_MAX_POOL=100 -DJDBC_MAX_IDLE_TIME=300000 -DJDBC_MAX_WAIT_TIME=5000″
# since 1.2, the JAVA_HOME need to be set to run BE process.
# JAVA_HOME=/path/to/jdk/
# https://github.com/apache/doris/blob/master/docs/zh-CN/community/developer-guide/debug-tool.md#jemalloc-heap-profile
# https://jemalloc.net/jemalloc.3.html
JEMALLOC_CONF=“percpu_arena:percpu,background_thread:true,metadata_thp:auto,muzzy_decay_ms:15000,dirty_decay_ms:15000,oversize_threshold:0,lg_tcache_max:20,prof:false,lg_prof_interval:32,lg_prof_sample:19,prof_gdump:false,prof_accum:false,prof_leak:false,prof_final:false“
JEMALLOC_PROF_PRFIX=““
# INFO, WARNING, ERROR, FATAL
sys_log_level = ERROR
# ports for admin, web, heartbeat service
be_port = 9060
webserver_port = 9040
heartbeat_service_port = 9050
brpc_port = 8060
# HTTPS configures
enable_https = false
# path of certificate in PEM format.
ssl_certificate_path = „$DORIS_HOME/conf/cert.pem“
# path of private key in PEM format.
ssl_private_key_path = „$DORIS_HOME/conf/key.pem“
# enable auth check
enable_auth = false
# Choose one if there are more than one ip except loopback address.
# Note that there should at most one ip match this list.
# If no ip match this rule, will choose one randomly.
# use CIDR format, e.g. 10.10.10.0/24 or IP format, e.g. 10.10.10.1
# Default value is empty.
# priority_networks = 10.10.10.0/24;192.168.0.0/16
priority_networks = 192.168.42.0/24
# data root path, separate by ‚;‘
# you can specify the storage medium of each root path, HDD or SSD
# you can add capacity limit at the end of each root path, separate by ‚,‘
# eg:
# storage_root_path = /home/disk1/doris.HDD,50;/home/disk2/doris.SSD,1;/home/disk2/doris
# /home/disk1/doris.HDD, capacity limit is 50GB, HDD;
# /home/disk2/doris.SSD, capacity limit is 1GB, SSD;
# /home/disk2/doris, capacity limit is disk capacity, HDD(default)
#
# you also can specify the properties by setting ‚<property>:<value>‘, separate by ‚,‘
# property ‚medium‘ has a higher priority than the extension of path
#
# Default value is ${DORIS_HOME}/storage, you should create it by hand.
storage_root_path = ${DORIS_HOME}/storage
# Default dirs to put jdbc drivers,default value is ${DORIS_HOME}/jdbc_drivers
jdbc_drivers_dir = ${DORIS_HOME}/jdbc_drivers
# Advanced configurations
sys_log_dir = ${DORIS_HOME}/log
# sys_log_roll_mode = SIZE-MB-1024
# sys_log_roll_num = 10
# sys_log_verbose_modules = *
# log_buffer_level = -1
# palo_cgroups
Swap deaktivieren
Es wird empfohlen, auf den Backends den Swap zu deaktivieren, da es sonst zu Fehlern kommen kann – also machen wir das auch:
- sudo swapoff -a
- sudo systemctl disable zramswap
- sudo systemctl disable dphys-swapfile
Doris Frontend stoppen mit
- /opt/doris/bin/start_fe.sh –daemon
Doris Cluster starten mit
./start_doris.sh
Scriptinhalt von start_doris.sh
#!/bin/bash
# check for root -> its not allowed
if [ $EUID -eq 0 ] ; then
echo „This script cannot be run as root“
exit 1
fi
# check for running java processes
if [ $(jps |grep DorisFE |wc -l) -gt 0 ]
then
echo „java processes running, please check with jps and ps -ef…..“;
exit 1;
fi
echo „“
echo „##########################################################################“
echo „starting doris frontend (fe) + backend (be)…..“
echo „##########################################################################“
cd /opt/doris/
/opt/doris/bin/start_fe.sh –daemon
ssh hduser@pi4b01 ’source ~/.profile && /opt/doris/bin/start_be.sh –daemon‘ > /dev/null 2>&1
ssh hduser@pi4b02 ’source ~/.profile && /opt/doris/bin/start_be.sh –daemon‘ > /dev/null 2>&1
#/opt/doris_broker/bin/start_broker.sh –daemon
#ssh hduser@h3cl02 ’source ~/.profile && /opt/doris_broker/bin/start_broker.sh –daemon‘
#ssh hduser@h3cl03 ’source ~/.profile && /opt/doris_broker/bin/start_broker.sh –daemon‘
while [ $(netstat -tulpen 2>/dev/null |grep 9030 |wc -l) -lt 1 ]
do
sleep 1;
done
while [ $(mysql -h 192.168.42.33 -P 9030 -uroot -e ‚SHOW BACKENDS\G;‘ |grep -E ‚Alive: true’| tr -s ‚ ‚ |wc -l) -lt 2 ]
do
sleep 1;
done
echo „“
echo „Frontends Info:“
mysql -h 192.168.42.33 -P 9030 -uroot -e ‚SHOW FRONTENDS\G;‘ |grep -E ‚Host:|Alive:‘ |tr -s ‚ ‚
echo „“
echo „Backends Info:“
mysql -h 192.168.42.33 -P 9030 -uroot -e ‚SHOW BACKENDS\G;‘ |grep -E ‚Host:|Alive:‘ |tr -s ‚ ‚
echo „“
echo „##########################################################################“
echo „cluster started, please check with jps…..“
echo „##########################################################################“
Cluster Status checken
- mysql -h pi5b -P 9030 -uroot -e „SHOW FRONTENDS\G;“
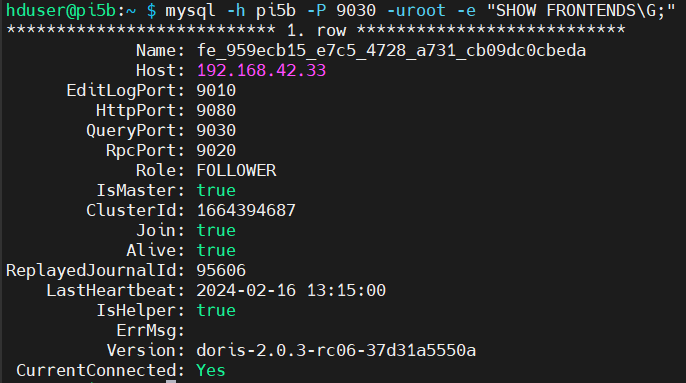
- mysql -h pi5b -P 9030 -uroot -e „SHOW BACKENDS\G;“
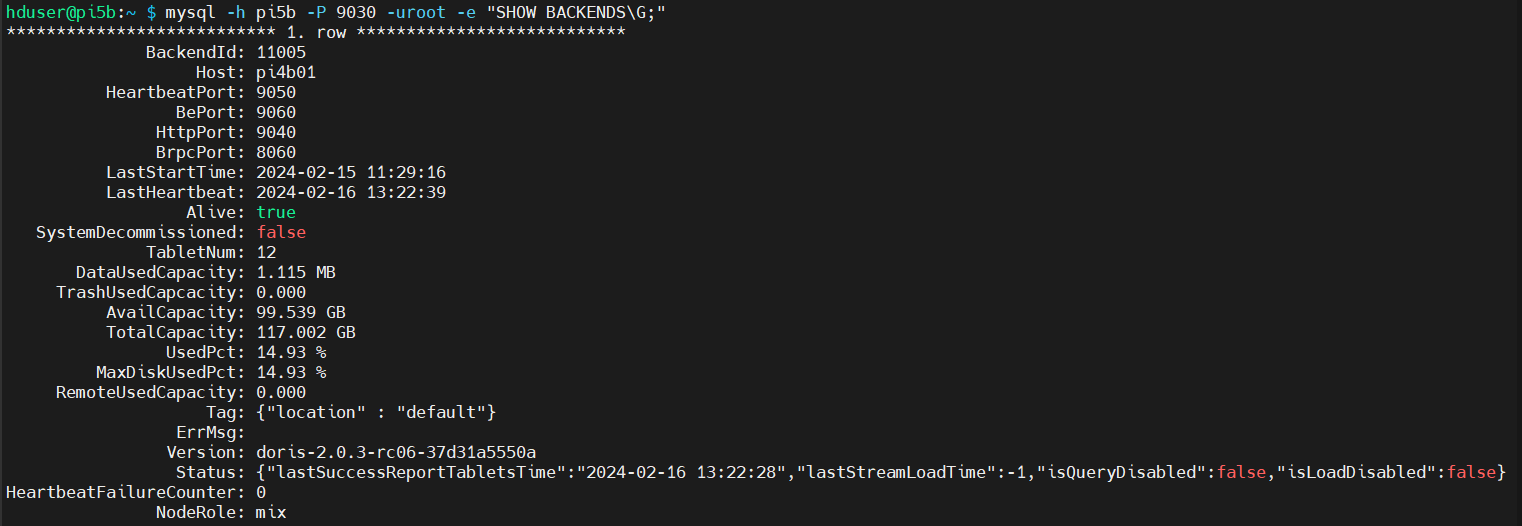
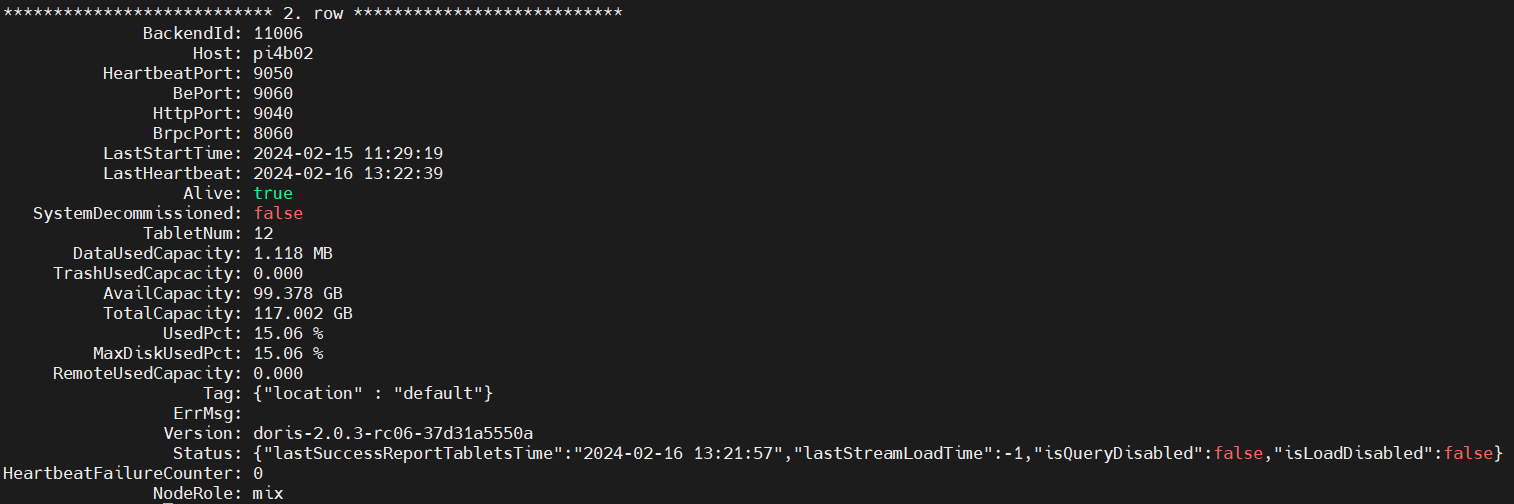
Den Doris Cluster stoppen wir mit
./stop_doris.sh
Scriptinhalt von stop_doris.sh
#!/bin/bash
# check for root -> its not allowed
if [ $EUID -eq 0 ] ; then
echo „This script cannot be run as root“
exit 1
fi
echo „“
echo „##########################################################################“
echo „stopping doris frontend (fe) + backend (be)…..“
echo „##########################################################################“
ssh hduser@pi4b01 ’source ~/.profile && /opt/doris/bin/stop_be.sh‘
ssh hduser@pi4b02 ’source ~/.profile && /opt/doris/bin/stop_be.sh‘
/opt/doris/bin/stop_fe.sh
echo „“
echo „##########################################################################“
echo „cluster stopped, please check with jps and ps -ef…..“
echo „##########################################################################“
In unserem nächsten Blog-Artikel im nächsten Monat geht es dann weiter…